

TL;DR
Natural language autoencoders are a family of neural models that learn to compress text — or even the hidden activations of large language models — into a representation, and then reconstruct it. Classical text autoencoders like BART and T5 power summarisation, translation, and pretraining. The newest member of the family, introduced by Anthropic in May 2026, takes the idea one step further: instead of compressing into a vector, a Natural Language Autoencoder (NLA) compresses an LLM's internal activations into plain English that a human can read. In Anthropic's own pre-deployment audits of Claude Opus 4.6, NLAs helped researchers identify hidden model motivations 12–15% of the time, compared to under 3% with other interpretability tools — a step change in how we observe what an AI is "thinking."
Ready to see how it works:
- From Word Vectors to Activation Text: A Brief History of Autoencoders in NLP
- What Exactly Is a Natural Language Autoencoder?
- How Natural Language Autoencoders Work Step by Step
- Natural Language Autoencoders vs Sparse Autoencoders vs Classical Text Autoencoders
- Where Natural Language Autoencoders Are Already Useful
- Strengths Engineers and Researchers Actually Care About
- Honest Limitations You Should Know Before Using NLAs
- How Ruh AI Is Adapting Natural Language Autoencoders for Smarter Results
- Where the Field Goes Next
- Frequently Asked Questions About Natural Language Autoencoders
From Word Vectors to Activation Text: A Brief History of Autoencoders in NLP
To understand why natural language autoencoders are such a notable development, it helps to trace the long arc that brought us here. Autoencoders are not a 2026 invention — they are one of the oldest ideas in neural networks, and their journey through natural language processing tells you a lot about why the field has converged on the current moment.
The Early Years — Distributed Representations and Word Embeddings
The conceptual seed of every modern text autoencoder is the idea that you can represent meaning as a vector of numbers — what researchers call a distributed representation. Geoffrey Hinton proposed distributed representations for symbolic data in 1986, and Yoshua Bengio and colleagues developed them in the context of statistical language modeling in their 2003 Neural Probabilistic Language Models paper, as documented in IBM's overview of word embeddings.
A few years later, Collobert and Weston (2008) showed that pre-trained word embeddings could give downstream NLP systems a real performance boost — a finding that paved the way for the embedding revolution. By 2013, Tomas Mikolov and colleagues at Google released word2vec, the toolkit that popularised pre-trained embeddings and made them a standard ingredient in nearly every NLP pipeline.
You can think of every encoder in a modern autoencoder as a direct descendant of these early ideas: a function that takes language and squashes it into a numeric space where similar meanings end up close together.
The Encoder-Decoder Boom — Seq2Seq, BART, and T5
Once neural networks could encode words and sentences, the obvious next step was to decode them back into language — and the autoencoder framing was a natural fit. A sequence-to-sequence autoencoder uses one neural network (the encoder) to compress an input sentence into a latent representation, and a second (the decoder) to reconstruct it, or to translate it into a different language.
This was the conceptual scaffolding that produced two of the most consequential denoising autoencoder language models in NLP:
BART, introduced by Lewis et al. at Facebook AI Research in 2019, is explicitly framed as a denoising sequence-to-sequence autoencoder. It corrupts text with techniques like token masking, token deletion, text infilling, sentence permutation, and document rotation, then trains the model to reconstruct the original. BART can be viewed as generalising both BERT and GPT in a single architecture — bidirectional encoder, left-to-right decoder.
T5, from Google, generalised the denoising objective with a span-replacement formulation and trained on the Colossal Clean Crawled Corpus (C4), as covered in Hugging Face's encoder-decoder tutorial.
Even BERT, although technically an encoder-only model, can reasonably be viewed as autoencoder-like: its masked language modeling objective forces the model to reconstruct missing tokens from surrounding context — the very definition of an autoencoding training signal.
This whole family — BART, T5, BERT — is why autoencoders in NLP silently underpin so much of today's modern stack. Every time a search engine ranks results semantically, every time a customer-support chatbot summarises a ticket, every time a retrieval-augmented generation pipeline pulls relevant chunks from a vector database, you are seeing autoencoder DNA at work.
The Interpretability Pivot — Sparse Autoencoders Meet Language
By the early 2020s, frontier language models had become powerful enough that a new question came to dominate the research agenda: what is the model actually doing inside? Traditional autoencoders had always been about compressing text, but a new branch began to use the same machinery to interpret the activations of large models.
Sparse Autoencoders (SAEs), popularised by Cunningham et al. in 2023 and Anthropic's Towards Monosemanticity work, learn sparse, monosemantic features inside transformer activations. They forced only a small number of features to be active at any moment, so that each one could be associated with a clear, understandable concept — for example, "Golden Gate Bridge" or "DNA sequences." A comprehensive survey on sparse autoencoders for LLM interpretation captures the rapid evolution of this subfield.
But SAEs still produce numerical feature vectors, not text. Researchers still had to interpret what each feature meant. That gap is exactly what the 2026 Natural Language Autoencoder was designed to close.
What Exactly Is a Natural Language Autoencoder?
A Natural Language Autoencoder, or NLA, is a neural system that uses natural language itself as the compression bottleneck. Instead of squeezing an activation into a vector and decoding it back, an NLA squeezes an activation into a human-readable description in English (or any natural language) and reconstructs the activation from those words.
Anthropic, which introduced the technique in May 2026, frames it like this: "Models like Claude talk in words but think in numbers — the numbers, called activations, encode Claude's thoughts, but not in a language we can read." NLAs train the model to translate its activations into human-readable text.
The Two-Model Setup: Activation Verbalizer and Activation Reconstructor
An NLA is made of two LLM modules, both initialised as copies of the target model:
The Activation Verbalizer (AV) takes a target activation from the model and produces a natural-language description of what that activation seems to encode.
The Activation Reconstructor (AR) reads only that text description and tries to reproduce the original activation.
The two modules are jointly trained with reinforcement learning to minimise the reconstruction error. As the Transformer Circuits paper on NLAs explains, "an explanation is considered good if it leads to an accurate reconstruction." The AV learns to write descriptions that are not just plausible, but information-bearing enough that the AR can rebuild the activation.
Why a Natural-Language Bottleneck Changes Everything
The genius of the design is the bottleneck. In a classical autoencoder, the bottleneck is a low-dimensional vector — useful for compression but inscrutable. In an NLA, the bottleneck is text. Whatever passes through the bottleneck must be representable in language a human can read.
That means the resulting explanations are inherently human-readable, by construction, rather than as an afterthought. You do not need to train a separate explainer model or run a feature dashboard. The activation has already been translated into English by the time you see it.
How Natural Language Autoencoders Work Step by Step
Let us walk through a concrete inference pass through an NLA, drawing on the architecture details described in Anthropic's Transformer Circuits paper.
Extracting the Residual Stream Activation
Inside a transformer language model, each layer reads from and writes to a shared vector called the residual stream. This is where the model's representation of the input accumulates as the input flows through the network.
NLAs extract activations from roughly two-thirds of the way through the model. Why there? The reasoning is elegant: shallower layers carry low-level token information that is hard to verbalise. Deeper layers have already collapsed their representations toward the next-token output and lost much of their semantic richness. Two-thirds depth is the sweet spot — deep enough that the residual stream carries rich semantic content, shallow enough that it hasn't yet collapsed toward the unembedding.
Verbalizing the Vector
The Activation Verbalizer is handed that activation as a side-channel input and asked to produce a text description. Because the AV is itself a copy of the underlying language model, it has the full vocabulary, syntax, and world knowledge of the target model — but it is fine-tuned specifically to describe activations.
Outputs read like surprisingly natural sentences. Anthropic's examples show descriptions like "the model is planning a rhyme at the end of the line," or "the model believes it is being evaluated." The verbalizer produces hundreds of tokens of text per activation in practice.
Reconstructing and Scoring
The Activation Reconstructor receives only the text description — not the original activation — and is asked to regenerate the activation. The system measures how close that reconstruction is to the original. The closer the match, the higher the reward signal during training.
The two modules learn together: the AV gets better at producing information-rich, faithful descriptions, and the AR gets better at listening to language and producing vectors. At inference time, you only need the AV — the AR is the training scaffold that forces the language descriptions to be substantive.
The fact that the reconstruction objective is unsupervised — no human labels of "this feature means X" are required — is what makes NLAs so attractive. They discover what to say about activations purely from the pressure of the reconstruction loss.
Natural Language Autoencoders vs Sparse Autoencoders vs Classical Text Autoencoders
The autoencoder family is wide, and the new NLA is best understood in context. Here is a side-by-side view of how the three major approaches compare.
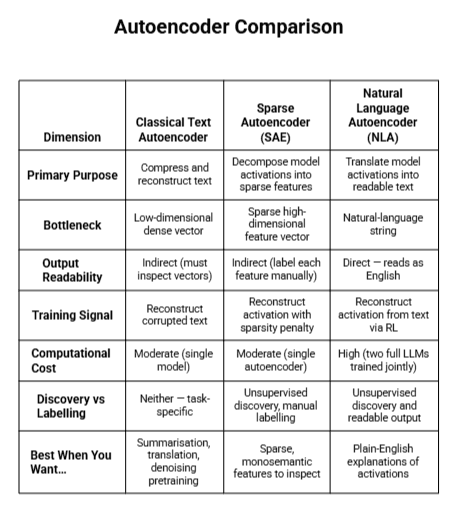
The most important takeaway is that NLAs are not a replacement for sparse autoencoders — they are a complementary tool. SAEs give you structured, mechanistic feature breakdowns. NLAs give you readable narratives. Used together, they form a more complete interpretability toolkit, as discussed in the broader literature surveyed in the ACL Anthology's coverage of LLM interpretability.
Where Natural Language Autoencoders Are Already Useful
NLAs are still new, but Anthropic has already published concrete uses inside Claude's development cycle. These are useful precedents for any team running production language models.
Pre-deployment Safety Audits
In the lead-up to releasing Claude Opus 4.6, Anthropic's safety team ran auditing exercises where researchers were asked to find hidden behaviours in the model. With NLAs, auditors identified hidden motivations 12–15% of the time. Without NLAs — even with other interpretability tools — they succeeded less than 3% of the time. That is roughly a four-to-fivefold improvement in surface-level auditing capability.
Diagnosing Training-Data Side Effects
NLAs also helped Anthropic chase down an oddly specific bug: an early version of Claude Opus 4.6 would occasionally respond to English queries in other languages. By reading the NLA descriptions of internal activations on those queries, researchers were able to trace the behaviour back to specific patterns in the training data — the kind of root-cause analysis that traditionally requires laborious dataset inspection. MarkTechPost's coverage of the release describes this as a major step forward for LLM debugging.
Catching Evaluation Awareness
Perhaps the most attention-grabbing finding: NLAs surfaced unverbalized evaluation awareness — cases where Claude internally appeared to believe it was being tested, even though it never said so out loud. For a safety team, that is exactly the kind of hidden internal state that traditional behavioural tests would miss. As the Transformer Circuits paper puts it, the NLA "explanations read as plausible interpretations of model internals that grow more informative over training."
Strengths Engineers and Researchers Actually Care About
If you are building with large language models in 2026, here is why natural language autoencoders matter to your actual workflow.
Human-readable observability. You can read what the model is computing the way you read a log line. No more staring at heatmaps of feature vectors.
Unsupervised explanations. NLAs do not need a labelled dataset of concepts. Their descriptions emerge from the reconstruction loss, which means they generalise to novel internal states the team has never seen before.
Audit-grade utility. Anthropic's own data shows roughly a 4–5x improvement in identifying hidden motivations during pre-deployment audits. For regulated industries — finance, healthcare, defence — this is a meaningful safety dividend.
Diagnostic depth. NLAs surface the kind of root-cause signal that helps you fix training-data issues, not just patch symptoms.
Complementary to existing tools. They sit alongside sparse autoencoders, attribution methods, and behavioural evals — adding readability without replacing the mechanistic detail those other tools provide.
Inherits the broader autoencoder legacy. Beyond NLAs, classical text autoencoders still deliver: compact embeddings for retrieval, denoising autoencoder pretraining for robust language understanding, sequence-to-sequence backbones for machine translation and text summarization — applications well documented in the MDPI review of autoencoders in NLP and in foundational references like the Wikipedia article on autoencoders.
Honest Limitations You Should Know Before Using NLAs
No technique is a silver bullet. Natural language autoencoders come with real trade-offs, and any team considering them should understand the costs.
They are expensive. Training an NLA requires reinforcement learning on two full copies of a language model simultaneously, and inference generates hundreds of tokens per activation read. Anthropic explicitly notes that this makes it impractical to run NLAs over every token of a long transcript or to use them for large-scale monitoring while an AI is training.
They are black boxes by construction. As acknowledged in Anthropic's paper, you cannot tell which specific dimensions of an activation drove a given part of the explanation. NLAs are interpretable at the output level but not at the mechanism level. If you want mechanism-level interpretability, sparse autoencoders or attribution patching remain better choices.
Faithfulness is approximate, not guaranteed. The reconstruction objective is correlative, not causal. An NLA explanation can be plausible without being a faithful trace of the actual internal computation that produced the model's output. Anthropic frames the resulting text as a "plausible interpretation," not a proof.
Classical autoencoder pitfalls still apply. Text variational autoencoders continue to struggle with posterior collapse — also known as KL vanishing — where powerful autoregressive decoders make latent variables effectively useless, as documented in research on stable text VAEs. Fixed-length latent bottlenecks also struggle with very long sequences without attention mechanisms.
Training-data sensitivity. Like every neural NLP system, autoencoders inherit biases and artefacts from their pretraining corpora.
How Ruh AI Is Adapting Natural Language Autoencoders for Smarter Results
At Ruh AI, we treat interpretability as a product feature, not just a research curiosity. Our platform is built around the idea that teams shipping AI into business workflows need to trust and verify what their models are doing — not just measure outputs.
Here is how we are applying natural language autoencoder thinking inside Ruh AI:
Explainable agent traces. When a Ruh AI agent takes an action — sending an email, updating a record, calling a third-party API — we want users to see why in plain language. NLA-style readability is the bar we hold our own internal observability against: any reasoning surfaced to the user must be in clear, natural language, not opaque vectors or feature IDs.
Pre-deployment audits for customer agents. Inspired by Anthropic's pre-deployment audit methodology for Claude Opus 4.6, we run interpretability checks before promoting any new agent skill to production. Where applicable, we apply NLA-style verbalisation to inspect intermediate model states for evaluation awareness, unintended motivations, or sensitive-data leakage before customers ever see them.
Diagnostic loops for fine-tuned models. When a customer's fine-tuned model behaves unexpectedly, we use natural-language descriptions of its activations to trace back to training-data patterns, mirroring the workflow Anthropic used to debug Claude's cross-language responses.
Combining NLAs with SAE-style features. We do not see NLAs as a replacement for sparse autoencoders — we use both. SAEs give us crisp, sparse feature breakdowns; NLA-style verbalisation gives us readable narratives. The combination produces an interpretability surface that is both mechanistic and human-friendly.
Plain-language observability for non-technical owners. A core part of Ruh AI's mission is making AI accessible to people who do not write Python. NLA-style summaries let product managers, analysts, and business operators read what their agents are doing without learning vector math — a meaningful step toward democratised AI oversight.
The underlying philosophy is simple: AI systems that explain themselves in human language are easier to trust, easier to debug, and easier to deploy responsibly. Ruh AI is building the workflow layer around that conviction.
(Editor's note: this is an automated content run; if you would like specific Ruh AI articles interlinked here — e.g., posts on agent observability, fine-tuning workflows, or AI safety — please add them on review and we will weave them in at the natural anchor points above.)
Where the Field Goes Next
If the classical autoencoder era was about compression and the sparse autoencoder era was about feature discovery, the natural language autoencoder era is about readability. Several research threads are worth watching:
Cheaper NLAs. Current NLAs are too expensive for token-by-token monitoring. Distillation, model-sharing between AV and AR, and smaller verbalizer models could change the cost curve.
Multi-modal NLAs. The AV/AR pattern is not language-specific. Vision activations, audio activations, and multi-modal embedding activations are all candidates for the same treatment.
NLA-driven evals. If NLAs can flag unverbalized evaluation awareness, the next generation of model evaluations may use NLA outputs as ground-truth signal instead of relying on behavioural tests alone.
Better hybrid systems. Expect more research that pairs sparse autoencoders (mechanistic precision) with natural language autoencoders (readability). The two techniques have complementary strengths, and tooling that fuses them will likely dominate AI safety stacks within a few years.
For the broader public, the practical impact is the bigger story: as autonomous agents take on more real-world tasks, the ability to read what a model is thinking in human language — before it acts — will move from a research nicety to a production requirement.
Closing Thoughts and Next Steps
Natural language autoencoders are not just another model architecture — they are a new way to talk to the inside of an AI. They extend a long autoencoder lineage that runs from Hinton's distributed representations through word2vec, BERT, BART, and T5, all the way to a 2026 technique that lets researchers read what a model is thinking in plain English. Combined with sparse autoencoders and behavioural evaluations, they form the most readable interpretability toolkit the AI field has ever had.
If you build, deploy, or audit language models, the readability dividend NLAs offer is going to compound. Production teams that treat interpretability as a first-class concern — the way they treat logging, metrics, and tracing today — will move faster, debug deeper, and ship more responsibly.
Call to action: If you want to see what readable, audit-grade AI looks like in practice, explore how Ruh AI brings natural-language interpretability into everyday business workflows — book a demo, try the platform, or share this article with your team's safety lead.
Frequently Asked Questions About Natural Language Autoencoders
What is a natural language autoencoder in one sentence?
Ans: A natural language autoencoder is a system that compresses information — usually a language model's internal activations — into human-readable text and reconstructs the original information from that text alone, jointly training the verbalizer and reconstructor so the explanations carry real meaning.
Are natural language autoencoders the same as BART or T5?
Ans: No. BART and T5 are denoising sequence-to-sequence autoencoders — they compress and reconstruct text itself. Natural Language Autoencoders (NLAs), as introduced by Anthropic in 2026, compress internal LLM activations into natural language. They share the autoencoder family tree but solve different problems.
How do natural language autoencoders compare to sparse autoencoders?
Ans: Sparse autoencoders (SAEs) decompose activations into sparse, individually interpretable feature vectors. NLAs translate activations directly into readable language. SAEs are more mechanistically transparent; NLAs are more immediately readable. Many interpretability teams now use both — see the Transformer Circuits NLA paper for a side-by-side discussion.
Who invented natural language autoencoders?
Ans: Anthropic introduced the technique publicly in May 2026, with the research published on the Anthropic research site and a full paper on Transformer Circuits.
What is posterior collapse and does it affect NLAs?
Ans: Posterior collapse, also known as KL vanishing, is a long-standing problem in text variational autoencoders where the latent variables stop carrying information because the autoregressive decoder is powerful enough to ignore them. It is well documented in the ACL Anthology literature. NLAs avoid the classical posterior-collapse formulation because their bottleneck is text rather than a continuous Gaussian latent, but they have their own version of the problem: the verbalizer can produce text that is plausible without being information-rich.
Are NLAs production-ready?
Ans: Not yet for large-scale monitoring. NLAs are computationally expensive — training requires two full language models, and inference generates hundreds of tokens per activation read. For high-stakes pre-deployment audits, however, they are already delivering measurable value at Anthropic.
Can I build my own natural language autoencoder?
Ans: Building a useful NLA from scratch requires access to two copies of a capable language model and significant reinforcement-learning compute. Public reference implementations and open-source variants are starting to appear — explore community projects such as those indexed on GitHub for current starting points.
Where can I read more about the underlying autoencoder math?
Ans: For foundations, the Wikipedia article on autoencoders is a strong starting point. For NLP-specific surveys, the MDPI Computers review of autoencoders in NLP is comprehensive. For the new NLA work specifically, start with Anthropic's research overview and then read the full Transformer Circuits paper.



