

TL;DR / Summary
Vector databases are the hidden infrastructure powering modern AI systems. While tools like LLMs get the attention, vector databases enable them to actually retrieve relevant knowledge, personalize responses, and operate at scale.
At their core, vector databases store embeddings — numerical representations of data — and use Approximate Nearest Neighbor (ANN) algorithms to quickly find similar content based on meaning, not keywords. This is what makes semantic search, recommendations, and Retrieval-Augmented Generation (RAG) possible.
Traditional databases couldn’t handle this shift because they were built for exact matches, not similarity-based retrieval, leading to the rise of a new category of purpose-built systems.
Ready to see how it all works? Here’s a breakdown of the key elements:
- The Invisible Engine Behind Modern AI
- What Is a Vector Database? The Non-Technical Explanation
- Where It All Began — The Origin Story
- The Science That Made It Possible — Embeddings Explained
- How Vector Search Actually Works
- Why Traditional Databases Couldn't Keep Up
- The Top 5 Vector Databases of 2025–2026
- Side-by-Side Comparison
- How Vector Databases Are Transforming Real Industries
- The Honest Truth — Risks and Limitations
- Pros and Cons: The Complete Breakdown
- How to Pick the Right One for Your Project
- What the Future Holds
- How Ruh AI Is Putting Vector Databases to Work
- Final Verdict
- Frequently Asked Questions
The Invisible Engine Behind Modern AI
There is a piece of infrastructure sitting underneath almost every AI product you use today. It is not a large language model. It is not a GPU cluster. It is not even a cloud provider. It is a vector database — and most people building AI products only discover it exists when their system starts breaking at scale.
When you ask a customer support chatbot a question and it pulls the exact right paragraph from a 500-page product manual, that is vector search. When Spotify recommends a song that somehow perfectly matches your mood even though you've never heard the artist, that is vector search. When your company's internal AI SDR finds the right contract clause from a folder of 10,000 legal documents in under a second, that is vector search.
The rise of large language models like GPT-4, Claude, and Gemini captured all the headlines between 2022 and 2025. But quietly, behind the scenes, a parallel revolution was underway in how AI systems store, retrieve, and reason over information. That revolution is the vector database — and by 2026, it has moved from experimental infrastructure to the absolute backbone of modern AI systems.
This blog is the complete story: where vector databases came from, why they exist, how the top five options differ from each other, what they make possible, and what you should genuinely worry about when using them.
What Is a Vector Database? The Non-Technical Explanation
Before we go deep, let us make sure we are starting from the same place.
Imagine you are trying to organize every book ever written, not by author name or publication date, but by the emotional feeling they give you. Books that make you feel hopeful cluster together on one shelf. Books that give you existential dread cluster on another. Books that make you laugh cluster somewhere else. Now imagine doing this not just for feeling, but for every possible dimension of meaning simultaneously — theme, writing style, vocabulary complexity, political tone, narrative structure, and hundreds more.
That is, roughly speaking, what a vector embedding does. It converts any piece of content — a sentence, an image, a product description, a user behavior log — into a list of numbers (called a vector) where each number encodes a specific learned trait. Similar content produces similar numbers. Similar numbers cluster in the same mathematical neighborhood.
A vector database is a system purpose-built to store billions of these numerical representations and, critically, to answer the question: "Which stored vectors are mathematically closest to this new one?" — in milliseconds, at scale.
That capability — finding meaning-based similarity at speed — is what powers the modern AI stack.
Where It All Began — The Origin Story
For decades, search meant keyword matching. Systems like Apache Lucene indexed every word and matched queries to exact terms. It worked for structured lookups, but it fundamentally could not understand meaning — search "cardiac arrest" and miss every document that only said "heart attack." Developers patched the gap with synonym dictionaries and stemming rules. It was never quite right.
The turning point came in 2013 when Google's Tomas Mikolov published Word2Vec — a neural network that learned to represent words as numerical vectors by training on billions of sentences. The revelation was that meaning could be expressed as geometry: king − man + woman ≈ queen. No hand-coded rules. Just a model that learned semantic relationships automatically.
Google's BERT in 2018 pushed this further, generating contextual embeddings where meaning shifted with context, and covering entire sentences — not just individual words. By 2019–2020, embedding models were good enough to power real semantic search. The problem was infrastructure: no existing database could store and query them at scale. PostgreSQL arrays required full table scans. Facebook's Faiss was a library, not a database. Elasticsearch's vector field was bolted on, not native.
That gap created a new category. The founding timeline is tight and deliberate:
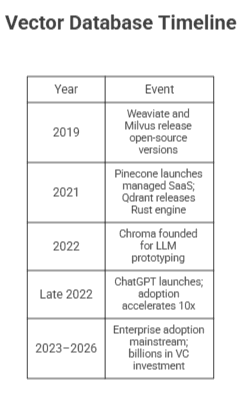
ChatGPT was the ignition. Suddenly millions of developers needed RAG (Retrieval-Augmented Generation) — systems where LLMs reference private data instead of hallucinating. RAG requires a vector database. The industry had arrived, and these five databases were ready for it. For a broader look at how this intelligence layer is reshaping business workflows, see Ruh AI's deep-dive on the AI in MLOps revolution.
The Science That Made It Possible — Embeddings Explained
A neural network trained on billions of examples learns to compress the meaning of any input — a sentence, an image, a user action — into a fixed list of floating-point numbers called a vector embedding. A typical text embedding has 768 to 1,536 dimensions, each encoding a latent trait the model discovered: formality, abstraction, sentiment, topic, and hundreds more. The model is never told what to look for; it learns these dimensions entirely from patterns in the training data.
The result is that meaning becomes geometry. Similar content produces vectors that are geometrically close together. Dissimilar content produces vectors that are far apart. Searching for "puppy playing" returns results about "dog having fun" — not because the words match, but because their vectors occupy the same neighborhood of mathematical space.
Proximity is measured using two common formulas: cosine similarity (the angle between two vectors — direction matters, not magnitude) and Euclidean distance (straight-line distance between two points). Both serve the same purpose: turning "how related are these two things?" into a number a computer can rank.
Modern applications use two complementary vector types simultaneously:
Dense vectors — arrays where most values are non-zero — capture semantic intent. A query for "how do I fix my account?" matches "Account Troubleshooting Guide" with zero word overlap, because the intent is the same.
Sparse vectors — arrays where most values are zero, with non-zero values for specific tokens — capture exact lexical matches. They are ideal for product codes, proper names, technical acronyms, and version numbers that dense vectors occasionally miss.
The state of the art is hybrid search: both types run in parallel, and their results are fused using algorithms like Reciprocal Rank Fusion (RRF) or weighted linear combination. The semantic richness of dense vectors pairs with the lexical precision of sparse vectors — delivering search quality that neither method achieves alone.
How Vector Search Actually Works
The Brute Force Problem
If you stored 100 million vectors, each with 1,536 dimensions, and wanted to find the 10 most similar to a new query vector, the brute-force approach would require comparing every stored vector to the query. That is 100 million × 1,536 = 153.6 billion floating-point operations per query. Even on fast hardware, this takes seconds — completely unacceptable for a real-time application.
Approximate Nearest Neighbor (ANN) Algorithms
The solution is to trade a small amount of precision for an enormous gain in speed. Approximate Nearest Neighbor (ANN) algorithms find results that are very close to the true nearest neighbors — perhaps not the absolute closest, but close enough for applications where "good enough" is genuinely good enough.
The leading ANN algorithm in production vector databases today is HNSW (Hierarchical Navigable Small World), which works by building a layered graph structure:
How HNSW navigates a search:
Query Vector Arrives
│
▼
┌─────────────────────────────────────┐
│ TOP LAYER (Highway) │ Long-range jumps across vector space
│ Few nodes, fast skip │ — like getting on a motorway
└───────────┬─────────────────────────┘
│ Jump to approximate region
▼
┌─────────────────────────────────────┐
│ MID LAYERS │ Progressively finer navigation
│ Balancing speed/acc. │ — like taking main roads
└───────────┬─────────────────────────┘
│ Narrow down neighborhood
▼
┌─────────────────────────────────────┐
│ BOTTOM LAYER (Local) │ Precise neighbor identification
│ Dense connections │ — like walking the last street
└───────────┬─────────────────────────┘
│
▼
Top-K Nearest Neighbors Returned
Instead of 153.6 billion calculations, HNSW typically performs only a few hundred distance comparisons — achieving sub-20ms query latency without GPU acceleration, and sub-5ms with GPU acceleration in systems like Milvus.
The trade-off: HNSW is not guaranteed to return the mathematically perfect nearest neighbor every time. In practice, for semantic search and recommendation, missing the absolute closest vector by a tiny margin is completely unnoticeable to users.
Why Traditional Databases Couldn't Keep Up
The question naturally arises: why couldn't existing databases — PostgreSQL, MySQL, MongoDB, Elasticsearch — simply add vector support and call it done?
The honest answer is that some of them have tried. PostgreSQL has the pgvector extension. Elasticsearch has its k-NN plugin. MongoDB Atlas has vector search. Redis has the Vector Similarity Search (VSS) module. These are all real and useful — and for smaller datasets or teams already deeply invested in those ecosystems, they are completely valid options.
But they carry fundamental limitations:
They were not designed for this access pattern. Relational and document databases are optimized for exact matches, range queries, and joins. The internal data structures — B-trees, inverted indexes — are designed for structured data. Adding ANN search is an extension, not a native capability, and extensions rarely match the performance of purpose-built systems.
They cannot reach the performance ceiling that dedicated vector databases achieve. At 100 million vectors and beyond, the performance gap between a dedicated vector database and a general-purpose database with vector extensions becomes stark. Purpose-built systems like Milvus can leverage GPU acceleration, custom memory layouts for vector data, and distributed query planning that general-purpose databases simply cannot match.
Hybrid search is difficult to optimize across both paradigms simultaneously. Combining dense vector ANN search with sparse keyword filtering and structured metadata constraints in a single query plan is architecturally complex. Vector databases are designed to do exactly this; general-purpose databases have to bolt it together.
This is why a dedicated category of databases emerged — and why, by 2026, most serious AI production systems use one.
The Top 5 Vector Databases of 2025–2026
1. Pinecone — The Managed Enterprise Powerhouse
"If Pinecone were a car, it would be a Tesla Model S: expensive, effortlessly fast, requires zero mechanical knowledge, and you are completely dependent on the manufacturer."
Background
Pinecone was founded in 2021 by Edo Liberty, a former Amazon AI researcher, with a clear thesis: most teams building AI applications should not have to manage database infrastructure. They should write code, not configure Kubernetes clusters. Pinecone raised over $100 million in venture funding and became the first commercially successful fully managed vector database.
Its positioning as the "iPhone of vector databases" is apt: it is opinionated, tightly integrated, deliberately simple on the surface, and extraordinarily polished. You interact with it entirely through an API. There are no servers to configure. There are no clusters to scale. There are no index rebuild jobs to manage.
How It Works
Pinecone uses a proprietary indexing engine that combines aspects of HNSW with its own optimizations. Its serverless architecture automatically allocates and deallocates compute resources in response to query load. When you upsert (insert or update) a vector, it becomes queryable in real-time — there is no batch processing window or index rebuild cycle.
Its sparse-dense index allows a single query to simultaneously perform semantic vector search and keyword matching, returning a fused result set without requiring the developer to manage two separate pipelines.
Strengths in Production
- Developers can go from zero to their first semantic search query in under 15 minutes
- Consistent ~20ms query latency under production load, regardless of index size
- Real-time indexing — vectors are queryable the moment they are inserted
- Namespace-based multi-tenancy for isolating data per customer or application
The Real Cost Picture
Pinecone's pricing follows a SaaS model:
- Free tier: Up to 1 million vectors — genuinely useful for prototyping and small applications
- Standard production: Starting at approximately $70/month for 5 million vectors
- At scale: Costs can reach thousands of dollars per month for hundreds of millions of vectors — significantly more expensive than self-hosted alternatives
For startups with no DevOps capacity, this premium is often worth it. For mature engineering organizations with infrastructure teams, the cost-versus-control calculation becomes harder to justify.
2. Milvus — The High-Performance Open-Source Beast
"Milvus is the F-16 fighter jet of vector databases: extraordinarily powerful, requires a trained pilot to operate, and built for missions where performance is the only metric that matters."
Background
Milvus was created by Zilliz, a San Francisco-based startup founded by Charles Xue and Xiaofan Luan, former database engineers who recognized in 2018 that no existing system could handle the AI embedding workloads they were encountering in production. Milvus 1.0 was released as open source in 2019 and later donated to the Linux Foundation AI & Data project — ensuring it remains community-governed and free forever.
By 2025, Milvus had become the gold standard for organizations operating at billion-scale vector deployments. It is used by companies including Salesforce, Walmart, and dozens of enterprise AI platforms where maximum throughput is non-negotiable.
How It Works
Milvus is built as a fully distributed, cloud-native system. Its architecture separates storage and compute — allowing each layer to scale independently. At its core is support for multiple indexing algorithms that can be selected based on workload characteristics:
- HNSW: Best for high recall and real-time queries on datasets under 100M vectors
- IVF_FLAT / IVF_PQ: Inverted file index with optional product quantization — balances speed and memory
- DiskANN: Enables queries on datasets that exceed RAM capacity by spilling to disk intelligently
- GPU_IVF_FLAT / GPU_BRUTE_FORCE: Leverages NVIDIA GPU acceleration for sub-5ms latency at extreme scale
With GPU acceleration, Milvus can handle over 10,000 queries per second with sub-5ms latency — performance that is simply unreachable by managed SaaS systems.
The Infrastructure Reality
Running Milvus in production is not trivial. A proper deployment requires Kubernetes, separate services for metadata (etcd), object storage (MinIO or S3), message queuing (Pulsar or Kafka), and careful resource allocation across query and index nodes. The first-time setup realistically takes an experienced DevOps engineer several days to get right.
The upside is total control: you choose the hardware, the cloud provider, the networking, the backup strategy, and the indexing algorithm. For organizations with specific compliance, latency, or cost requirements, this control is worth the overhead.
Zilliz Cloud — the managed Milvus service — bridges this gap for teams that want Milvus's performance without full self-management.
3. Weaviate — The Swiss Army Knife
"Weaviate is the multi-tool of vector databases: it does more things natively than anything else in the category, and the right engineer will find it invaluable."
Background
Weaviate was founded in Amsterdam in 2019 by Bob van Luijt, who was frustrated by how difficult it was to build knowledge graph and semantic search applications. The initial vision was broader than most vector databases — Weaviate was conceived as an AI-native database that could store objects, understand their relationships, automatically generate embeddings, and retrieve them semantically.
This breadth is both Weaviate's greatest strength and the source of its complexity.
What Makes Weaviate Distinct
Weaviate's most unique capability is built-in vectorization modules — integrations with OpenAI, Cohere, Google PaLM, and Hugging Face that allow Weaviate to generate embeddings automatically when data is inserted. Most vector databases require you to generate embeddings separately (using an embedding model API) and then insert the resulting vectors. Weaviate can eliminate this step entirely.
Its GraphQL API sets it apart architecturally. Where Pinecone and Qdrant use REST APIs, Weaviate's GraphQL interface allows complex, nested queries that can traverse relationships between objects — more like a graph database than a traditional key-value store. For applications with rich data models, this expressiveness is genuinely valuable.
Weaviate also offers:
- Native BM25 + vector hybrid search in a single query
- Multi-tenancy at the schema level — each tenant gets isolated storage and indexing
- Multi-modal support — text, images, and audio can coexist in the same collection
The Trade-Offs
The breadth of Weaviate's feature set comes with resource overhead. Running Weaviate's built-in modules (especially auto-vectorization) consumes more memory and compute than a leaner system like Qdrant or Chroma. At extreme scale, performance benchmarks suggest Milvus maintains a lead in raw throughput.
For teams that value feature richness and schema expressiveness over extreme performance, Weaviate is the natural choice.
4. Qdrant — The Developer Darling
"Qdrant is the precision scalpel of vector databases: sleek, fast, incredibly well-engineered, and preferred by developers who care deeply about doing one thing perfectly."
Background
Qdrant was founded in 2021 by Andrei Vasnetsov and Luis Crespo Barrios, engineers who had worked extensively with vector search at scale and were deeply unsatisfied with the performance and memory efficiency of existing solutions. Their decision to write Qdrant in Rust — a systems programming language known for memory safety and performance without garbage collection — was deliberate and consequential.
By 2024–2025, Qdrant had become a community favorite among developers who valued clean API design, predictable performance, and the engineering rigor that Rust enforces. Its GitHub star growth rate was among the fastest in the category.
The Memory Efficiency Breakthrough
Qdrant's standout technical achievement is its approach to vector quantization. Using Product Quantization (PQ), Qdrant can compress vectors into codebook representations that reduce RAM usage by up to 97% — meaning a dataset that would require 100 GB of RAM in a naive float32 representation can be served from 3 GB.
This is not merely a cost optimization — it changes what is possible on given hardware. Billion-scale deployments that would otherwise require dozens of high-memory nodes can run on a fraction of the infrastructure.
The Payload Filtering Advantage
Qdrant's payload system — storing rich JSON metadata alongside each vector and applying filters during vector search rather than after — is widely regarded as the most sophisticated metadata filtering implementation in the category. This matters enormously for real applications:
- Filter by user_id before searching to ensure data isolation in multi-tenant systems
- Filter by timestamp range to search only recent documents
- Filter by geographic coordinates for location-aware applications
- Apply complex nested boolean logic without post-retrieval filtering overhead
For applications where business logic governs what results are permissible (nearly all enterprise applications), Qdrant's payload system significantly reduces engineering complexity and query latency simultaneously.
5. Chroma — The Developer-Friendly Prototyping Layer
"Chroma is the skateboard of vector databases: not built for the highway, but it will get you where you are going faster than anything else in the neighborhood."
Background
Chroma was founded in 2022 by Jeff Huber and Anton Troynikov, veterans of Scale AI and other ML infrastructure companies, in direct response to the LLM application explosion triggered by ChatGPT. Their observation was that thousands of developers were suddenly trying to build RAG applications and semantic search tools for the first time — and every existing vector database was far too complex for an initial prototype.
Chroma's design philosophy is radical simplicity: a vector database that requires zero infrastructure setup, runs in-process with your Python application, and integrates with LangChain and LlamaIndex out of the box.
How Chroma Works
In its default embedded mode, Chroma runs as a Python library within your application process — there is no separate server, no Docker container, no configuration file. You import Chroma, create a collection, insert documents (Chroma can even generate embeddings for you if you connect an embedding function), and query — all in under 20 lines of Python.
python
import chromadb
client = chromadb.Client()
collection = client.create_collection("my_docs")
collection.add(documents=["This is a document about AI"], ids=["doc1"])
results = collection.query(query_texts=["what is AI?"], n_results=1)
This simplicity makes Chroma uniquely powerful for education, experimentation, hackathons, and early-stage product validation. The gap between "idea" and "working demo" is measured in minutes, not days.
The Ceiling
Chroma's simplicity is purchased at the cost of scale. Its embedded mode is not designed for concurrent production traffic. It lacks GPU acceleration, advanced quantization, multi-tenancy, and many of the enterprise features that production deployments require. It is not a system you would run serving millions of queries per day.
The honest positioning of Chroma is: it is the best possible database for the first 80% of an AI project's lifecycle — prototyping, validation, demos. When the project moves to production at scale, migrating to Pinecone, Milvus, or Qdrant is the expected path.
Side-by-Side Comparison

How Vector Databases Are Transforming Real Industries
Vector databases are not niche infrastructure — they are actively reshaping how core industries operate.
Healthcare: Pharmaceutical researchers query billions of molecular structures to find compounds with similar signatures to a known drug — narrowing clinical trial candidates from years of lab screening to hours of vector search. A 2023 Nature study demonstrated how embedding-based retrieval accelerates drug discovery at scale. Clinical staff retrieve patient records semantically: querying "chest tightness and arm numbness" surfaces records documented as "angina" or "cardiac episode" with no synonym map required. Ruh AI has written extensively on how AI employees are augmenting human excellence in healthcare — vector retrieval is the infrastructure layer that makes those workflows possible.
Legal and Compliance: Law firms run semantic search across thousands of contracts and regulatory filings. A query for "force majeure provisions related to supply chain disruption" surfaces relevant clauses regardless of exact wording — cutting junior lawyer review time dramatically. Compliance systems flag transaction records whose behavioral vectors diverge from a customer's historical cluster, catching violations before they escalate.
E-Commerce and Retail: A query for "cozy autumn outfit for a weekend hike" returns results matching aesthetic intent — not just products tagged "autumn" and "hiking." According to McKinsey, personalization engines that move beyond keyword matching drive 10–15% revenue uplifts. Recommendation engines embed full purchase histories as behavioral vectors, finding users whose patterns are geometrically close and enabling genuinely individual-level discovery rather than segment-level approximations. This same personalization logic powers AI-driven customer journey mapping — where vector similarity determines which touchpoint to surface next for each prospect.
Enterprise Knowledge Management: Companies embed entire institutional knowledge bases — wikis, Slack archives, engineering specs, incident postmortems — and expose them through AI assistants. A new engineer asking "how does our deployment pipeline work?" gets a synthesized answer from across all internal sources rather than spending a week navigating folder structures. IBM's research on RAG documents significant productivity gains from this approach in enterprise settings. For a practical playbook on standing this up across an organization, Ruh AI's complete implementation guide for using AI in organizations covers the full deployment lifecycle.
Financial Services: Portfolio managers query earnings transcripts, SEC filings, and analyst reports semantically in real time. Fraud detection has moved from static rules (flag if amount > $X and location ≠ home) to vector behavioral modeling — transactions landing far from a user's historical vector cluster are flagged, catching fraud patterns no rule anticipated. The Bank for International Settlements has documented the effectiveness of ML-based anomaly detection over rule-based systems in financial fraud contexts. Ruh AI explores how AI employees are reshaping financial services at the operational layer where vector search is most directly applied.
Education and Research: Academic literature search spans tens of millions of papers semantically. Researchers query mechanisms and concepts rather than keywords, retrieving relevant work even when different fields use different terminology for the same phenomenon. Semantic Scholar, powered by AI2, is a leading example of vector search deployed at research-scale across 200M+ papers.
The Honest Truth — Risks and Limitations
No technology is without its shadow side. A complete picture of vector databases requires engaging seriously with the risks.
Risk 1: The Approximate Nearest Neighbor Precision Gap
Every major vector database uses ANN algorithms that are, by definition, approximate. The system does not guarantee returning the mathematically closest vector — it returns results that are very close, very fast. For most applications, this trade-off is completely acceptable.
But consider a scenario where this matters: a medical diagnostic system searches for similar patient cases to inform a treatment decision. If the ANN algorithm misses the single most similar case — the one with the most directly relevant outcome data — the clinical consequences could be significant. Organizations deploying vector search in high-stakes decision contexts must carefully evaluate whether "close enough" is genuinely close enough for their specific use case.
Risk 2: The Embedding Model Dependency Problem
Your vector database is only as good as the embedding model generating your vectors. This creates a dangerous dependency: if you change your embedding model, every vector in your database must be regenerated.
This is not a minor operational concern. If you have 500 million vectors generated with OpenAI's text-embedding-ada-002 model and upgrade to a newer, better model, you face a choice between a massive re-embedding computation job (expensive and time-consuming) or running two models simultaneously (complex and costly). Many organizations discover this problem at the worst possible time — when they want to improve search quality by upgrading their embedding model.
Planning for embedding model versioning from day one is essential and often overlooked.
Risk 3: Vendor Lock-In (Particularly for Pinecone)
Pinecone's fully managed model is its greatest strength and its greatest risk. There is no self-hosted option, no export mechanism that directly transfers to another vector database, and no standard query language that would allow you to swap providers. Organizations that build deeply on Pinecone are making a long-term bet on Pinecone's pricing, availability, and feature roadmap.
This is not hypothetical. SaaS infrastructure vendors have historically adjusted pricing significantly as they mature and raise prices. Building a critical AI feature on a single managed provider without an exit plan is an organizational risk that deserves explicit governance.
Risk 4: Data Privacy and Compliance in the Cloud
For managed vector databases like Pinecone (and the cloud offerings of others), the embedding vectors — which encode the semantic meaning of potentially sensitive documents — are stored on third-party infrastructure.
This raises genuine compliance questions. If your vectors are generated from HIPAA-covered health records, financial data subject to GDPR, or classified government information, storing those semantically rich representations on a third-party cloud may violate your data governance obligations — even if the original documents never leave your environment. Legal and compliance teams must be involved in this architectural decision.
Risk 5: Operational Complexity at Scale (Self-Hosted)
The "free" open-source vector databases are not actually free in practice. Running Milvus in production requires Kubernetes expertise, continuous monitoring, capacity planning, index maintenance, backup strategies, and on-call engineering support. Organizations that adopt Milvus or Weaviate without adequately staffing for this operational overhead routinely encounter production incidents — index corruption, query node overload, memory exhaustion — that a managed service would have prevented.
The total cost of ownership for self-hosted vector databases frequently exceeds initial estimates by 2–3x when engineering time is properly accounted for.
Risk 6: Cold Start and Index Rebuild Latency
Many ANN indexing algorithms — especially HNSW — require a complete or partial index rebuild when data volumes change substantially. For most self-hosted vector databases, adding a large batch of new vectors can trigger a rebuild process that takes minutes to hours and degrades query performance during the rebuild window.
Applications that require real-time indexing without any performance degradation during data ingestion are limited to managed services like Pinecone (which handles this transparently) or must architect careful offline/online index separation strategies.
Risk 7: No Standardized Query Language
Unlike SQL, which is portable across dozens of relational databases, vector databases each have their own proprietary API and SDK. Migrating from Qdrant to Milvus, or from Weaviate to Pinecone, requires rewriting query logic, re-evaluating index configurations, and potentially restructuring metadata schemas. This switching cost is not prohibitive, but it is real — and it means that early architectural decisions are difficult to reverse cheaply.
Pros and Cons: The Complete Breakdown
Pros
Semantic understanding beyond keywords — vector search retrieves by intent and meaning, not character matching. "How do I cancel my subscription?" finds "Account Cancellation Guide" with zero word overlap.
Multi-modal in a single system — text, images, audio, and code can coexist in the same database, enabling cross-modal search patterns that were previously impossible without separate pipelines.
RAG is only possible with a vector database — Retrieval-Augmented Generation, the technique that gives LLMs access to private and current data, is architecturally dependent on fast semantic retrieval. No vector database, no RAG. This principle sits at the core of how Ruh AI's Sarah SDR retrieves contextually relevant prospect data to personalise every outreach at scale — without hallucination.
Real-time personalization at individual scale — behavioral vectors update continuously, enabling per-user personalization rather than segment-level approximations.
Native composability with the AI stack — LangChain, LlamaIndex, Haystack, and AutoGen all have first-class integrations with every major vector database, dramatically reducing integration engineering.
Cost-efficient at scale via quantization — product quantization can cut RAM usage by up to 97%, making billion-vector deployments viable on commodity hardware rather than requiring GPU superclusters.
Metadata filtering enforces business logic during search — structured constraints (permissions, price ranges, geographic bounds) apply during the vector search, not after, keeping query latency low even with complex rules.
Cons
Results are approximate, not guaranteed — ANN algorithms are fast precisely because they skip the exhaustive comparison. For high-stakes decisions (clinical, legal, financial), "very good neighbors" may not be good enough — this deserves explicit architectural evaluation.
Open-source is not free to operate — self-hosted Milvus or Weaviate requires Kubernetes expertise, monitoring, index maintenance, and on-call support. Total cost of ownership regularly runs 2–3x higher than initial estimates when engineering time is included.
Embedding model changes force full re-indexing — upgrading to a better embedding model means regenerating every vector in the database. At 500M+ vectors, this is a significant compute and time cost that teams frequently discover at the worst possible moment. This is why self-improving AI systems built on RLHF must plan embedding versioning as a first-class architectural concern, not an afterthought.
No standard query language — every vector database has its own API and SDK. Unlike SQL, there is no portable abstraction. Switching providers means rewriting query logic from scratch.
Managed services raise compliance concerns — storing vectors (which encode the semantic meaning of potentially sensitive content) on third-party cloud infrastructure may conflict with GDPR, HIPAA, or internal data governance requirements.
Index rebuilds degrade performance during ingestion — many self-hosted ANN implementations require a partial or full index rebuild after large batch inserts, causing query latency spikes during the rebuild window.
Ecosystem maturity lags relational databases — observability tooling, schema migration patterns, governance frameworks, and debugging workflows are all significantly less mature than their PostgreSQL or MongoDB equivalents.
How to Pick the Right One for Your Project?
Rather than prescribing a single answer, the right choice depends on four dimensions: scale, team capability, cost tolerance, and control needs.
HIGH SCALE
│
MILVUS │ WEAVIATE
│
LOW CONTROL ───────────────┼─────────────── HIGH CONTROL
│
PINECONE │ QDRANT
│
LOW SCALE
│
CHROMA (Prototyping Layer)
Choose Pinecone when: Your team's time is more valuable than infrastructure cost, you need to ship in days not weeks, and you can accept SaaS pricing and vendor lock-in as the price of simplicity.
Choose Milvus when: You are operating at scale that makes self-hosting economically necessary, you have dedicated infrastructure engineers, and raw performance is more important than developer convenience.
Choose Weaviate when: Built-in vectorization is genuinely valuable for your architecture, GraphQL is already familiar to your team, or you need rich schema-level multi-tenancy for a SaaS product.
Choose Qdrant when: Complex metadata filtering is central to your application, memory efficiency is a budget or hardware constraint, or you value Rust-grade engineering rigor and a clean REST API.
Choose Chroma when: You are building your first AI feature, validating an idea, running a hackathon, or teaching — and you need to be productive immediately without infrastructure setup.
What the Future Holds
The vector database market in 2026 is moving fast in several directions simultaneously.
Multi-modal embeddings are becoming the default, not the exception. Models like OpenAI's CLIP and Google's Gemini embed text, images, and audio into a shared vector space — enabling cross-modal search — and vector databases are rushing to support them natively.
Agentic AI architectures are placing new demands on vector databases. AI agents that autonomously plan, reason, and act need not just fast retrieval but persistent memory — the ability to store episodic memories, learned preferences, and ongoing task state as vectors that update continuously. Vector databases are evolving to meet this need. Understanding how to design these agents reliably is critical — Ruh AI's guide on AI agents that refuse commands and the fatal design flaws is essential reading before deploying any agentic system in production. For teams building agents from scratch, prompt engineering for autonomous systems covers the production-ready patterns that make vector-backed agents actually reliable.
The managed vs. self-hosted gap is narrowing. Zilliz Cloud (managed Milvus), Qdrant Cloud, and Weaviate Cloud Services are making it progressively easier to access open-source performance without open-source operational overhead. The choice is becoming less binary.
Standardization pressure is building. As more enterprise buyers demand portability, industry consortia are exploring vector query standards. Whether a "SQL for vector databases" will emerge is unclear — but the market forces pushing toward portability are real.
How Ruh AI Is Putting Vector Databases to Work?
Understanding vector databases in theory is one thing. Deploying them inside real AI systems that generate pipeline, close deals, and serve customers at scale is another entirely. Ruh AI sits at that second frontier — and vector database infrastructure is woven into every layer of what the platform does.
The Core Problem Ruh AI Solves
Sales and revenue teams have always faced the same core retrieval problem: how do you surface the right message, for the right prospect, at the right moment — across thousands of simultaneous conversations, without a human in the loop for every touchpoint?
The answer, at the infrastructure level, is vector search. Every prospect interaction, every piece of company context, every past conversation, and every piece of intent signal gets embedded and stored. When Sarah, Ruh AI's AI SDR, engages a prospect, she is not templating a generic cold email. She is performing a semantic retrieval across the prospect's digital footprint, the company's product context, and a library of high-performing messaging — and synthesising a genuinely personalised outreach in real time.
This is exactly the RAG architecture described throughout this blog, applied to a revenue workflow.
Where Vector Search Shows Up in Ruh AI's Stack
Prospect Intelligence and Personalisation Traditional cold email outreach in 2026 lives or dies on relevance. Ruh AI's system embeds firmographic data, intent signals, job change alerts, LinkedIn activity, and prior engagement history as dense vectors. When a new prospect enters the pipeline, the nearest-neighbour retrieval identifies which messaging angles, case studies, and pain point framings have worked for the most similar prospects — and builds the outreach from that contextual foundation rather than from scratch.
Marketing Operations and Campaign Execution Marketing operations bottlenecks are frequently a retrieval problem in disguise: the right asset exists somewhere, but nobody can find it fast enough to include it in the campaign going out today. Vector search across the full content library — case studies, one-pagers, email sequences, social posts — means the system can surface the most semantically relevant content for any given campaign brief without manual curation.
Customer Journey Intelligence AI-driven customer journey mapping depends on understanding where each customer sits relative to the journeys of customers who preceded them. By embedding journey state as a vector — touchpoints visited, content consumed, signals fired — Ruh AI's system identifies which next action is most semantically similar to the actions that converted comparable accounts. This is collaborative filtering rebuilt on top of semantic embeddings rather than raw co-occurrence counts.
Financial Services and Healthcare Verticals The compliance requirements of financial services AI deployments and the sensitivity demands of healthcare AI systems make the choice of vector database architecture — self-hosted vs. managed, metadata filtering design, access control via namespace — genuinely consequential, not just a performance preference. Ruh AI's implementations in these verticals are built with the data governance principles covered in the risks section of this blog as hard constraints, not afterthoughts.
The Broader AI Employee Architecture
Ruh AI's vision extends beyond a single SDR agent. The AI employee model — where autonomous AI workers handle entire workflows end-to-end — is only viable when each agent can reliably retrieve the right context, remember prior interactions, and adapt its behaviour based on what has worked before. All three capabilities are vector database problems at their core:
- Context retrieval = semantic search over company knowledge and prospect history
- Memory = episodic vector storage that persists across sessions
- Adaptation = RLHF-driven self-improvement informed by what retrieval patterns correlated with successful outcomes
Building agents that actually work — rather than agents that refuse commands or fail in production — requires getting this retrieval layer right. The database choice, the embedding model, the metadata schema, and the hybrid search configuration are not implementation details. They are the foundation on which agent reliability is built.
Want to See It in Action?
If you are evaluating how vector-powered AI can transform your revenue operations, customer engagement, or internal knowledge workflows, the Ruh AI team is a conversation away. You can also browse the full Ruh AI blog for practical guides on deploying AI across sales, marketing, operations, and beyond — all built on the infrastructure foundations this article covers.
Vector databases represent one of the most significant infrastructure shifts in enterprise technology since the rise of NoSQL databases in the early 2010s. They were born from a genuine technical gap — the need for systems that could store and retrieve meaning rather than just data — and they have grown, in under a decade, from research curiosities to mission-critical production infrastructure.
The top five of 2025–2026 — Pinecone, Milvus, Weaviate, Qdrant, and Chroma — each represent a different answer to the same fundamental challenge, shaped by different design philosophies and optimized for different operational realities.
None of them is universally correct. All of them are genuinely impressive engineering.
The decision that matters is not which vector database is "best" in the abstract — it is which one best matches your team's capacity, your application's requirements, and your organization's risk tolerance. That decision, made thoughtfully with awareness of the trade-offs documented here, is the difference between vector search being a competitive advantage and vector search becoming an operational liability.
The new industrial revolution in AI is underway. These five databases are the infrastructure it runs on — and platforms like Ruh AI are the proof of what becomes possible when that infrastructure is deployed with intention.
Frequently Asked Questions
What is a vector database used for?
Ans: A vector database stores and searches numerical embeddings of unstructured data — text, images, audio, and code — finding content that is semantically similar to a query rather than matching exact words. The primary use cases are RAG (giving LLMs access to private knowledge without hallucinating), semantic search, recommendation engines, anomaly and fraud detection, and AI agent memory across sessions. For a practical breakdown of how RAG fits into an organisation's AI stack, see Ruh AI's implementation guide.
What is the difference between a vector database and a traditional database?
Ans: A traditional database answers "does this row exactly match these criteria?" A vector database answers "which stored items are most similar to this query?" The table below captures the key distinctions:
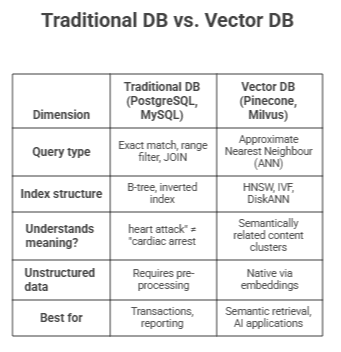
They are not competitors — most production AI systems use both. The relational database handles structured business data; the vector database handles the semantic retrieval layer that grounds AI responses in real context.
Which vector database should I choose for RAG?
Ans: Match your choice to your project stage and team capacity:
- Prototyping: Chroma — zero setup, Python-native, works with LangChain out of the box. Working RAG pipeline in under an hour.
- Small-to-mid production team: Pinecone — real-time indexing, native hybrid search, zero infrastructure management. Pay the cost premium to skip the DevOps overhead.
- Scale with infrastructure capability: Qdrant if access-control filtering is critical; Milvus if raw GPU-accelerated throughput is the priority.
- Schema-rich with auto-embedding: Weaviate eliminates the separate embedding pipeline step entirely.
Regardless of choice, prioritise hybrid search support above almost everything else. Pure vector search misses exact product codes, proper names, and technical identifiers — without hybrid search, your RAG system will hallucinate on those queries even when the right document is in the index.
What is the best free vector database?
Ans: All four open-source options — Milvus, Weaviate, Qdrant, and Chroma — are free under Apache 2.0. The best one depends on what "free" means in practice:
- Zero ops overhead → Chroma. Runs in-process, no server, no Docker. Ideal for prototyping.
- Free managed cloud tier → Qdrant Cloud. Permanent free tier, no credit card required, no Kubernetes needed.
- Free at any self-hosted scale → Milvus. Software is free regardless of dataset size; you pay for infrastructure and DevOps time instead.
- Pinecone's free tier caps at 1 million vectors — fine for prototyping, not a production-grade free solution.
One honest caveat: free software ≠ free to run. A production Milvus deployment typically costs $300–$800/month in infrastructure alone. Factor total cost of ownership into the decision, not just the licence.
Is pgvector better than specialised vector databases?
Ans: pgvector wins when: your team already runs PostgreSQL, your dataset is under 5 million vectors, you need transactional consistency between relational and vector data in the same operation, or SQL familiarity matters more than raw retrieval performance.
Specialised databases win decisively when: you exceed 10M vectors (pgvector's index rebuild times and memory overhead become painful), you need mature hybrid search (pgvector's sparse+dense support is nascent versus Pinecone or Weaviate's native implementations), you need GPU acceleration (unavailable in pgvector), or metadata filtering at scale matters — pgvector applies WHERE clauses after ANN search, not during, meaning you pay full scan cost before filtering.
The pragmatic rule: if vector search is a secondary feature alongside a relational application, start with pgvector. If vector retrieval is the core mechanism your AI system depends on, a purpose-built database will serve you better as you scale. Plan the migration before you need it, not after.



