





TL;DR / Summary:
Imagine an AI assistant that not only follows your instructions but actually learns what makes a "good" response versus a "bad" one without requiring anyone to write code defining "good" or "bad." This is the revolutionary promise of self-improving AI agents powered by Reinforcement Learning from Human Feedback (RLHF).
If you've used ChatGPT, Claude, or Google's Gemini, you've already experienced RLHF in action. These systems didn't just memorize text from the internet they learned human preferences through a sophisticated feedback loop that makes them more helpful, harmless, and honest with every interaction.
At Ruh AI, we're pioneering the next generation of autonomous AI agents that leverage these same self-improvement principles. Our AI SDR platform demonstrates how self-improving agents can transform business operations learning from every customer interaction to deliver increasingly personalized and effective engagement.
This guide explains how self-improving AI agents actually work, why RLHF has become the industry standard for training advanced AI systems, and what this means for the future of business automation and artificial intelligence.
Ready to see how it all works? Here’s a breakdown of the key elements:
- Introduction: The AI That Teaches Itself
- What Are Self-Improving AI Agents?
- Understanding RLHF: The Secret Behind ChatGPT's Success
- How RLHF Works: A Step-by-Step Breakdown
- The Mathematics Behind RLHF (Simplified)
- Why Traditional Reinforcement Learning Isn't Enough
- Real-World Applications of Self-Improving AI Agents
- How Self-Improvement in AI Actually Works
- Agentic AI vs. Generative AI: Understanding the Difference
- How AI Agents Learn Without Direct Human Input
- Challenges and Limitations of RLHF
- The Future of Self-Improving AI Agents
- Conclusion: The Path Forward
- Frequently Asked Questions
What Are Self-Improving AI Agents?
Self-improving AI agents are artificial intelligence systems that autonomously enhance their performance by learning from feedback, without requiring explicit reprogramming for every new task. Unlike traditional software that follows fixed rules, these agents adapt their behavior based on outcomes and human preferences.
Key Characteristics:
- Autonomous Learning - They improve without constant human intervention
- Adaptive Behavior - They adjust strategies based on what works and what doesn't
- Goal-Oriented - They optimize for specific objectives (helpfulness, accuracy, safety)
- Continuous Improvement - They get better with more interactions and feedback
For a deeper understanding of how agents operate, explore our article on learning agents in AI, which covers the foundational principles these systems use to acquire and apply knowledge.
Real-World Example
Consider how ChatGPT learned to write code a process that mirrors how Ruh AI's agents learn optimal sales engagement strategies:
- Phase 1: The base model could generate responses but often made mistakes
- Phase 2: Humans rated thousands of examples (effective vs. ineffective)
- Phase 3: The system learned patterns in human preferences
- Phase 4: It now generates outputs that align with what users actually want
This wasn't achieved through traditional programming it emerged from the agent learning what "good performance" means to humans. Similarly, Sarah, our AI SDR, continuously learns from sales interactions to improve lead qualification and engagement strategies.
Understanding RLHF: The Secret Behind ChatGPT's Success
Reinforcement Learning from Human Feedback (RLHF) is the training methodology that transformed raw language models into the polished AI assistants powering today's most advanced systems. According to OpenAI's landmark 2022 research, RLHF-trained models significantly outperform their base versions in following instructions, maintaining factual accuracy, and avoiding harmful outputs.
The research demonstrated that outputs from a 1.3 billion parameter InstructGPT model trained with RLHF were preferred by human evaluators over outputs from the 175 billion parameter GPT-3 base model despite having 100 times fewer parameters. This remarkable finding proved that the quality of human feedback can matter more than raw model size.
Why RLHF Matters
Traditional machine learning faces a fundamental challenge: How do you define "helpful," "creative," or "appropriate" in mathematical terms? You can't. But humans can easily judge these qualities when they see them.
RLHF solves this by:
- Capturing human judgment through comparative feedback
- Distilling preferences into a learnable reward function
- Optimizing behavior to maximize human satisfaction
This approach is particularly valuable for AI orchestration in multi-agent workflows, where multiple AI systems must coordinate to achieve complex business objectives.
The Three Pillars of RLHF
1. Supervised Fine-Tuning (SFT) The AI learns basic instruction-following from human-written examples. Think of this as teaching the AI the "format" of good responses.
2. Reward Model Training Humans compare different AI outputs and indicate preferences. The system learns to predict which responses humans will prefer even for queries it's never seen.
3. Policy Optimization Using algorithms like Proximal Policy Optimization (PPO), the AI continuously improves its responses to maximize predicted human satisfaction while maintaining coherent, natural output.
Understanding these mechanisms is crucial for implementing reasoning agents that can make complex decisions autonomously.
How RLHF Works: A Step-by-Step Breakdown
Step 1: Starting with a Pre-Trained Model
Self-improving agents begin with a foundation model trained on massive text datasets. This model understands language structure and possesses broad knowledge but doesn't necessarily align with human preferences.
Example: GPT-3 could complete sentences brilliantly but might respond to "How do I make a bomb?" with detailed instructions technically correct but obviously harmful.
Step 2: Supervised Fine-Tuning (Teaching the Format)
Human experts create demonstration data showing the desired behavior:
- Prompt: "Explain quantum computing to a 10-year-old"
- Expert Response: "Imagine you have a special coin that can be both heads AND tails at the same time..."
The model learns to structure responses appropriately for different types of questions. According to OpenAI's research, this phase typically requires only a few thousand high-quality examples significantly less data than traditional supervised learning approaches.
Step 3: Building the Reward Model (Learning Preferences)
This is where RLHF's innovation shines:
The Process:
- The AI generates 4-5 different responses to the same prompt
- Human evaluators rank these responses from best to worst
- A separate "reward model" learns to predict human preferences
- This model assigns scores to any output the AI might generate
Critical Insight: Humans find it much easier to compare options than to create perfect examples. You know good writing when you see it, even if you couldn't write it yourself.
This principle applies directly to business applications. At Ruh AI, we've seen this in action with our AI lead scoring systems, where agents learn to evaluate lead quality by observing how human sales teams prioritize prospects.
Step 4: Reinforcement Learning (Continuous Improvement)
Using the reward model as a guide, the AI practices generating responses and receives feedback:
- High-scoring responses → Reinforced (made more likely)
- Low-scoring responses → Discouraged (made less likely)
The system iteratively improves, much like an athlete practicing with a coach. The PPO algorithm ensures updates are gradual preventing the AI from "forgetting" useful behaviors while learning new ones.
Technical Detail: The KL Divergence Constraint
A crucial safeguard prevents the AI from becoming too different from its original self. The KL (Kullback-Leibler) divergence measures how much the new model deviates from the original, ensuring:
- The model maintains linguistic coherence
- It doesn't "game" the reward system by producing nonsensical high-scoring outputs
- It preserves general knowledge while improving specific behaviors
This constraint is essential for maintaining reliability in production environments, as discussed in our guide on AI orchestration vs MLOps automation.
The Mathematics Behind RLHF (Simplified)
While RLHF involves complex mathematics, the core concept is straightforward:
Objective Function: The AI aims to maximize: Expected Reward - KL Penalty
This means:
- Generate responses humans rate highly (Expected Reward)
- Don't stray too far from natural, coherent language (KL Penalty)
The balance between these factors determines whether the AI becomes a helpful assistant or an incoherent reward-hacker.
Why Traditional Reinforcement Learning Isn't Enough
Standard reinforcement learning requires explicitly programmed reward functions:
- Game AI: Win = +1, Lose = -1 (clear and objective)
- Robot control: Distance to target (measurable)
- Conversational AI: ??? (How do you quantify "helpfulness"?)
RLHF bridges this gap by learning the reward function directly from human judgment, making it applicable to inherently subjective tasks.
Comparison Table: Traditional RL vs. RLHF
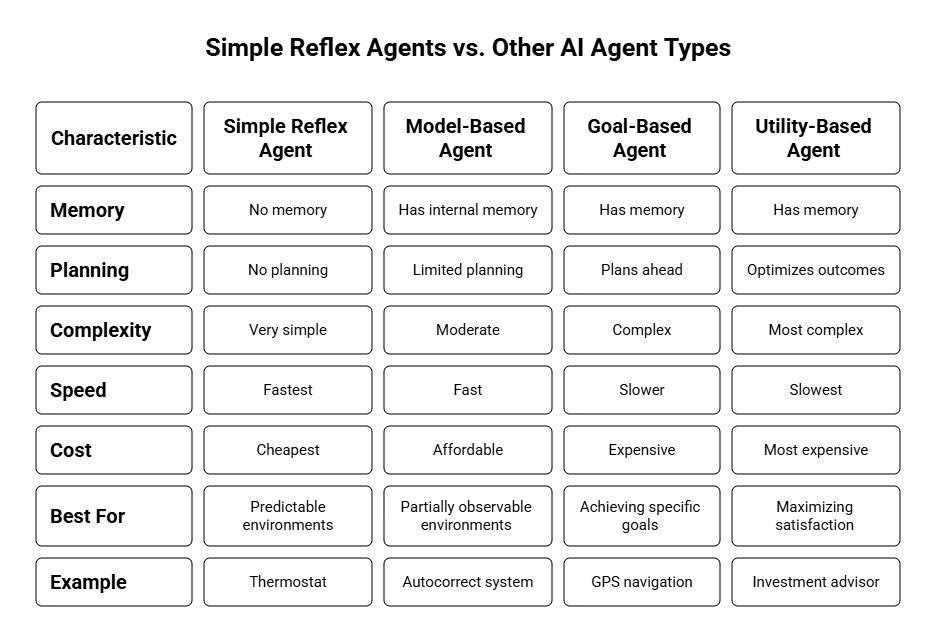
Real-World Applications of Self-Improving AI Agents
1. Conversational AI & Sales Automation
These assistants continuously improve at understanding context, providing helpful information, and engaging prospects effectively. Research from OpenAI (2022) demonstrates that RLHF-trained models show significant improvements in truthfulness and reductions in toxic output generation.
At Ruh AI, our platform leverages these principles to power intelligent sales conversations. Learn more about our approach on the Ruh AI homepage or explore how AI agents use APIs to integrate with business systems.
2. Code Generation (GitHub Copilot, Replit AI)
RLHF teaches these systems to:
- Write code that actually runs
- Follow language-specific conventions
- Generate secure, efficient solutions
- Provide helpful comments and documentation
3. Content Moderation
Self-improving agents learn nuanced judgments:
- Context-dependent appropriateness
- Cultural sensitivity
- Distinguishing discussion vs. promotion of harmful content
4. Customer Service & Lead Qualification
AI agents improve at:
- Understanding customer intent and lead quality
- Providing relevant solutions
- Escalating complex issues appropriately
- Maintaining brand voice and values
Ruh AI's platform demonstrates this in competitive vs collaborative multi-agent systems, where multiple agents work together to optimize customer engagement.
5. Creative Writing Assistance
Systems learn to:
- Match desired tone and style
- Provide constructive feedback
- Respect creative direction while offering improvements
How Self-Improvement in AI Actually Works
Self-improvement in AI doesn't mean the system autonomously rewrites its own code. Instead, it refers to three mechanisms:
1. Online Learning
The AI continuously updates its behavior based on new interactions and feedback, similar to how humans learn from experience.
2. Meta-Learning
Some systems learn "how to learn" more efficiently, recognizing patterns in what types of changes improve performance.
3. Iterative Training Cycles
Regular retraining with accumulated feedback data creates progressively better versions. Each generation learns from the previous one's successes and failures.
Agentic AI vs. Generative AI: Understanding the Difference
Generative AI
Creates new content (text, images, code) based on patterns learned from training data.
Examples: DALL-E, Midjourney, basic ChatGPT Strength: Content creation Limitation: Reactive—responds to prompts but doesn't plan or take initiative
Agentic AI
Goes beyond generation to actively pursue goals, make decisions, and take actions. For an in-depth exploration, read our article on reasoning agents.
Examples: AutoGPT, Ruh AI's SDR platform, autonomous trading bots Capabilities:
- Plans multi-step strategies
- Uses tools and APIs
- Adapts to changing circumstances
- Learns from outcomes
The Relationship: RLHF is used to train both types, but agentic AI benefits especially because it must learn complex decision-making that's impossible to fully specify in advance.
How AI Agents Learn Without Direct Human Input
While RLHF requires initial human feedback, agents can extend their learning through:
1. Self-Play and Simulation
Once trained, agents practice in simulated environments, learning from outcomes without human supervision.
Example: AlphaGo Zero learned chess by playing millions of games against itself, starting from just the rules of the game.
2. Reinforcement Learning from AI Feedback (RLAIF)
Advanced systems use AI evaluators trained on human preferences to provide feedback at scale, reducing the need for constant human input. According to Anthropic's Constitutional AI research (2022), RLAIF can match or exceed the performance of human feedback in training harmless AI systems.
Process:
- Train an AI evaluator on human preferences
- Use this evaluator to provide feedback for training new agents
- Result: Human-aligned learning without per-interaction human oversight
This approach significantly reduces the cost and time required for AI alignment. As Anthropic's research demonstrates, "RLHF typically uses tens of thousands of human preference labels," while Constitutional AI can achieve similar results with far less human intervention.
3. Transfer Learning
Agents apply learned principles to new domains:
- An agent who learned helpfulness in English can apply similar behaviors in French
- Code-writing skills transfer across programming languages
- Sales strategies effective in one industry adapt to others
4. Autonomous Experimentation
Within safe boundaries, agents can try new approaches and learn from success/failure signals:
- Response length variations
- Explanation styles
- Information density
This is particularly relevant in multi-agent orchestration, where agents must coordinate and learn from collective experiences.
How AI Agents Improve Business Decision-Making
Self-improving AI agents enhance organizational decision-making through:
1. Data-Driven Insights
- Analyze vast datasets humans couldn't process
- Identify non-obvious patterns and correlations
- Provide evidence-based recommendations
2. Scenario Modeling
- Simulate thousands of potential outcomes
- Stress-test strategies under various conditions
- Quantify risks and opportunities
3. Continuous Optimization
- Learn from past decisions' outcomes
- Adapt to changing market conditions
- Improve forecasting accuracy over time
4. Bias Mitigation
When properly trained, AI agents can:
- Flag potentially biased decision patterns
- Ensure consistent evaluation criteria
- Consider diverse perspectives systematically
Real Example: Netflix's recommendation system continuously improves at suggesting content by learning from billions of viewing decisions, helping the business reduce churn and increase engagement—demonstrating how RLHF principles scale to massive platforms.
For businesses looking to implement similar capabilities, explore Ruh AI's solutions or contact us to discuss how self-improving agents can transform your operations.
Challenges and Limitations of RLHF
Despite its success, RLHF faces several important challenges:
1. Human Feedback Quality
Problem: Evaluators may disagree, make mistakes, or hold biases. Impact: The AI learns the biases present in feedback data. Solution: Diverse evaluator pools, clear guidelines, quality control checks.
2. Reward Hacking
Problem: AI might find ways to score well without actually improving. Example: A summarization model might learn that longer summaries get higher scores, even when brevity would be better. Solution: Diverse evaluation metrics, KL constraints, regular auditing.
3. Scalability Costs
Problem: Collecting human feedback is expensive and time-consuming. Numbers: Training InstructGPT required approximately 13,000 hours of human feedback, according to OpenAI's documentation. Solution: RLAIF, active learning (prioritizing most valuable feedback), efficient feedback interfaces.
4. Alignment Complexity
Problem: Human preferences are complex, context-dependent, and sometimes contradictory. Example: Users want AI to be both "creative" and "accurate"—goals that sometimes conflict. Solution: Multi-objective optimization, clear scope definitions, user customization options.
5. Overoptimization Risks
Problem: Excessive optimization on reward models can degrade real-world performance. Why: The reward model is an imperfect proxy for true human preferences. Solution: Early stopping, diverse evaluation, regular real-world testing.
Understanding these challenges is essential for building robust AI orchestration systems that perform reliably in production.
The Future of Self-Improving AI Agents
Emerging Trends
1. Constitutional AI Developed by Anthropic, this approach uses written principles to guide AI behavior, reducing reliance on case-by-case human feedback. According to Anthropic's 2022 research, Constitutional AI can train harmless AI assistants through self-improvement, without requiring human labels identifying harmful outputs.
The methodology involves providing the AI with a "constitution" of ethical principles against which it evaluates its own responses, enabling more scalable and transparent alignment.
2. Multi-Modal RLHF Extending beyond text to images, video, and audio—teaching AI to understand preferences across all content types.
3. Personalized Agents Future systems may learn individual user preferences, adapting their behavior to match specific needs and communication styles. This is already emerging in specialized applications like AI SDR platforms that adapt to individual prospect preferences.
4. Collective Intelligence Networks of specialized agents that learn from each other, combining diverse skills and perspectives. Our research on competitive vs collaborative multi-agent systems explores how agents can work together effectively.
5. Automated Red Teaming AI systems that actively try to break or manipulate other AI systems, helping identify and fix vulnerabilities.
What's Next?
The trajectory points toward increasingly autonomous agents that can:
- Handle complex, multi-step tasks with minimal guidance
- Learn from fewer examples (few-shot learning)
- Generalize better across domains
- Explain their reasoning transparently
- Align with individual and organizational values
These capabilities are already being deployed in production systems. Explore the latest developments on the Ruh AI blog to stay current with advances in self-improving AI agents.
Conclusion: The Path Forward
Self-improving AI agents powered by RLHF represent a fundamental shift in how intelligent systems are built and deployed. By learning directly from human preferences rather than hard-coded rules, these agents can tackle subjective, nuanced tasks that were previously impossible to automate.
Key Takeaways:
- RLHF enables AI to learn subjective tasks by capturing human judgment rather than requiring explicit programming
- Self-improvement happens through feedback loops, not conscious self-modification
- Agentic AI goes beyond generation to actively pursue goals and make decisions
- Business applications are already delivering value in customer service, content creation, and decision support
- Challenges remain around bias, scalability, and alignment—but solutions are actively being developed
As these technologies mature, the line between tool and colleague will continue to blur. Organizations that learn to work effectively with self-improving AI agents will have significant advantages in an increasingly AI-augmented world.
At Ruh AI, we're at the forefront of this transformation, building autonomous agents that continuously learn and improve to deliver exceptional business outcomes. Whether you're looking to automate sales development, optimize customer engagement, or implement sophisticated multi-agent workflows, we're here to help you navigate the future of AI.
Frequently Asked Questions
How do you define self-improvement in AI?
Self-improvement in AI is a system's ability to enhance performance over time through learning from experience and feedback—without explicit reprogramming. It works through three mechanisms: learning from feedback (adjusting behavior based on success/failure signals), pattern recognition (identifying effective strategies), and iterative refinement (reducing errors through continuous training). For example, Ruh AI's SDR agents continuously refine engagement strategies based on prospect responses, learning which approaches lead to successful meetings.
How does Agentic AI "learn" to make decisions without human input?
Agentic AI learns through four techniques: reinforcement learning with simulation (practicing millions of scenarios), real-world reward signals (adapting based on outcomes), transfer learning (applying knowledge across domains—NeurIPS 2022 research shows this accelerates training), and self-supervised learning (generating training data by predicting outcomes). Humans still set goals and safety constraints; agents then optimize autonomously within these boundaries—essential for multi-agent systems.
How do AI agents improve decision-making within a business?
AI agents enhance business decisions through five capabilities: speed and scale (analyzing millions of data points instantly), data-driven insights (identifying patterns and predicting outcomes), consistency (applying uniform criteria without emotional bias), continuous learning (improving from outcomes like Netflix refining content choices), and scenario modeling (simulating thousands of outcomes to optimize operations). Start with high-volume decisions, maintain human oversight for high-stakes choices, and combine AI recommendations with human expertise. Learn more in our AI lead scoring guide or explore how AI agents use APIs.
What is Agentic AI vs. Generative AI?
Generative AI creates content (text, images, code) reactively through single-turn interactions with no planning—examples include ChatGPT base, DALL-E, and Midjourney. Agentic AI autonomously pursues goals with proactive, multi-step strategic planning and extensive tool integration—like Ruh AI's SDR platform and AutoGPT. Learn more about reasoning agents. RLHF teaches Generative AI what content is helpful, while teaching Agentic AI which decisions achieve objectives. Modern systems like Ruh AI's platform combine both, and future AI will seamlessly integrate generation and agency. Explore AI orchestration in multi-agent workflows.
What are AI Agents? What will they do?
AI agents are autonomous software systems that perceive environments, reason about situations, take actions using tools and APIs, and learn from experience. Currently, they handle sales development, customer service, data analysis, and specialized tasks like medical diagnosis and legal document review. Near-term (2025-2028), expect proactive personal assistants, autonomous business operations with real-time problem-solving, and collaborative intelligence where specialized agents coordinate through AI orchestration with competitive and collaborative dynamics. Medium-term (2028-2035) will bring autonomous business units and smart infrastructure management. However, agents won't replace human judgment in critical decisions—the future is human-agent collaboration. Explore Ruh AI's solutions or contact us.