



TL;DR / Summary
Vector databases are the hidden infrastructure powering modern AI systems, enabling machines to search, compare, and reason based on meaning rather than exact matches. Unlike traditional databases, they store high-dimensional embeddings—numerical representations of data—and use fast similarity search (often via HNSW indexing) to retrieve relevant information in milliseconds at massive scale.
They became essential with the rise of large language models and Retrieval-Augmented Generation (RAG), solving the problem of AI systems lacking access to real-time or proprietary data. Today, they power everything from semantic search and recommendations to fraud detection, healthcare insights, and autonomous AI agents.
However, they come with trade-offs: performance depends heavily on embedding quality, chunking strategy, and approximate search limitations; costs and memory requirements can scale rapidly; and debugging, security, and data freshness introduce real engineering challenges.
Despite these risks, vector databases are now foundational to AI architecture—acting as long-term memory for intelligent systems. As AI evolves toward agentic and multimodal systems, vector databases are becoming the cognitive backbone that enables AI to move from simple responses to real-world decision-making.
Ready to see how it all works? Here’s a breakdown of the key elements:
- The Industry Shift Nobody Saw Coming
- What a Vector Database Actually Is (Beyond the Textbook Definition)
- The Origin Story — When, Why, and How Vector Databases Were Born
- The Architecture Underneath — How It All Works
- How Vector Databases Entered the AI Industry
- Real-World Impact — Where Vector Databases Are Changing Everything
- The Risks — What Nobody Tells You
- Pros of Vector Databases
- Cons of Vector Databases
- The Landscape — Tools and Providers
- What Comes Next
- How Ruh AI Is Putting Vector Databases to Work in Agentic and Generative AI
- Final Word
- FAQ
The Industry Shift Nobody Saw Coming
There is a quiet revolution happening inside the servers that power your AI assistant, your Netflix recommendations, your bank's fraud detection system, and your workplace chatbot. It does not have a flashy name. It does not get keynote speeches at CES. But without it, nearly every product that feels "intelligent" in 2025 would not function the way it does.
That revolution is the vector database.
For decades, the tech industry ran on relational databases — structured grids of rows and columns that answered precise questions: "Give me all orders where customer_id = 4821." These systems were, and still are, extraordinary. But as artificial intelligence began consuming unstructured data — documents, images, conversations, audio clips — the old paradigm broke down. You cannot store the meaning of a paragraph in a SQL column. You cannot compare the visual similarity of two photographs with a WHERE clause.
The industry needed a new kind of database. One that does not ask "Does this row match my query exactly?" but instead asks: "Which stored data is most meaningfully similar to what I am looking for?"
That is the question vector databases were built to answer — and in doing so, they have become the foundational infrastructure of the modern AI era.
This blog is the complete story: where vector databases came from, how they work, why they matter, how they are reshaping entire industries, and what the risks of using them actually look like.
What a Vector Database Actually Is
Beyond the Simplified Definition
Most introductions to vector databases offer something like: "A vector database stores vector embeddings." That is technically accurate and practically useless — like saying a hospital is "a place that stores sick people."
Here is a more honest definition:
A vector database is a purpose-built storage and retrieval engine that stores high-dimensional numerical representations of data (called embeddings) and executes extraordinarily fast similarity searches across millions or billions of those representations in milliseconds.
The critical word is similarity. Not equality. Not keyword matching. Similarity — the same way a human brain recognises that "car crash" and "automobile accident" describe the same thing, that a photo of a golden retriever is more similar to a photo of a labrador than to a photo of a cactus, and that the sentence "my chest hurts and I cannot breathe" belongs to the same medical context as "symptoms of a heart attack."
Traditional databases are built for exactness. Vector databases are built for meaning.
The Three-Part Structure of Every Vector Record
Every record stored in a vector database contains three components:
1. The Unique ID A simple identifier that links the vector back to the original source document, image, or data object.
2. The Vector Embedding The numerical representation itself — an ordered array of floating-point numbers, typically anywhere from 384 to 4,096 dimensions long. For example:
[0.023, -0.417, 0.891, 0.004, -0.312, 0.758, ...]
Each number encodes a fragment of the data's meaning or features. Two pieces of text that discuss the same concept will produce vectors whose numbers are mathematically close to each other in the high-dimensional coordinate space.
3. The Payload / Metadata Structured attributes attached to the embedding that enable filtering:
json { "source": "product_catalog", "category": "running_shoes", "price": 89.99, "brand": "Nike", "in_stock": true }
This metadata is what enables hybrid search — combining semantic similarity with hard business rules, like "find me the most semantically relevant running shoes under $100 that are currently in stock."
The Origin Story
The early internet ran on keyword search — powerful for exact word matching, blind to meaning. That ceiling held until 2013, when Google's Word2Vec showed that words could be represented as vectors in mathematical space, making it possible to compute King − Man + Woman ≈ Queen. Meaning had become mathematics.
BERT (2018) and GPT (2018–2019) scaled this further, converting entire documents into dense semantic vectors. By 2021, OpenAI's CLIP did the same for images — embedding both text and pictures into a shared mathematical space. The problem that followed was infrastructural: traditional databases had no way to store or search millions of high-dimensional vectors efficiently. A brute-force scan across 10 million 1,536-dimensional vectors takes seconds — completely unacceptable for production AI.
The first purpose-built solutions emerged between 2019 and 2022 — Milvus (open-sourced 2019), Weaviate (2019), Pinecone (managed service, 2021), Qdrant (2021), and Chroma (2022). When ChatGPT launched in November 2022 and the LLM race began, every engineering team hit the same wall immediately: LLMs do not know your data. The solution — RAG — required a place to store and search proprietary knowledge. That place was a vector database. The category went from niche infrastructure to essential AI stack component in under two years, drawing hundreds of millions in venture capital and prompting every major cloud provider to ship a managed vector search service.
The Architecture Underneath
Four stages power every vector database in production:
1. Embedding Pipeline Raw content — documents, images, audio — is passed through an embedding model (OpenAI text-embedding-3-large, CLIP, Whisper, CodeBERT) and converted into a fixed-length numerical vector. Similar items produce geometrically close vectors. The embedding model is the intelligence layer; the database is the retrieval layer.
2. Indexing with HNSW The gold-standard indexing algorithm used by Pinecone, Qdrant, Milvus, and Weaviate. HNSW builds a multi-layered graph — sparse "highway" layers for long-range jumps across the dataset, dense "local street" layers for precision near the target. A search that would require 100 million distance calculations brute-force typically completes in a few hundred using HNSW — returning results in single-digit milliseconds. The trade-off: HNSW is approximate. It may occasionally miss the single nearest vector, which is an acceptable trade-off for nearly all production AI applications. Alternatives include IVF (cluster-based, memory-efficient) and Flat/brute-force (exact, only viable at small scale).
3. Similarity Metrics Three metrics cover the vast majority of use cases:

4. Metadata Filtering (Hybrid Search) Every embedding is stored alongside a structured payload (category, price, brand). Filters can be applied before (pre-filtering), after (post-filtering), or simultaneously with (inline filtering) the vector search. Inline filtering, used by advanced systems like Qdrant, is the most efficient — evaluating semantic similarity and metadata conditions in a single pass without discarding already-retrieved results.
How Vector Databases Entered the AI Industry
RAG — Solving the LLM Memory Problem LLMs are frozen at training. They have no access to your company's internal documents, last week's news, or your product data. RAG — Retrieval Augmented Generation (introduced by Lewis et al., NeurIPS 2020) solves this using a vector database as an external, queryable knowledge store:
- Documents are chunked, embedded, and stored in the vector database.
- At query time, the user's question is converted to an embedding.
- The database retrieves the top semantically relevant chunks.
- Those chunks are injected into the LLM prompt as context.
- The LLM responds using your actual data — not hallucinated, not outdated.
This pattern reduced hallucinations, eliminated knowledge cutoff constraints, and made domain-specific AI products viable. RAG is now the default architecture for enterprise AI assistants, support bots, legal tools, and internal knowledge systems. Companies like Ruh AI have taken this further — deploying RAG not just for static knowledge retrieval but as the memory backbone for fully autonomous AI employees that operate across financial services, healthcare, and sales workflows.
Semantic Search Vector search replaced keyword search across industries. Searching "heart attack symptoms" now surfaces literature on "myocardial infarction" and "cardiac arrest" — because their embeddings occupy the same region of semantic space. Legal search surfaces synonymous contract clauses. E-commerce surfaces visually or contextually similar products. Multilingual queries return results across languages without explicit translation.
Recommendations, Fraud Detection, and Biometrics Netflix, Spotify, and Amazon represent users and content as vectors — recommendations are nearest-neighbour lookups. Fraud detection flags transactions whose embeddings fall far outside the normal cluster. Facial recognition is a billion-scale vector similarity search. In every case, the common thread is the same: find what is most similar, fast.
Real-World Impact
Industries Being Transformed
Healthcare and Life Sciences Clinical AI assistants built on RAG can retrieve the most relevant medical literature, drug interaction data, and clinical guidelines in response to a physician's natural language query — grounded in the latest research, not a frozen training corpus. Diagnostic imaging systems use vector similarity to surface the most similar historical cases to a new scan. Genomic databases use embedding-based search to find functionally similar gene sequences. Ruh AI's research on AI in healthcare documents how vector-backed AI agents are augmenting clinical workflows without displacing the human judgment that patients depend on.
Financial Services Beyond fraud detection, financial institutions use vector search for regulatory compliance (surfacing relevant regulation paragraphs for a given contract clause), investment research (finding semantically similar market events to historical precedents), and customer service (RAG-powered assistants grounded in actual product and policy documentation). The Bank for International Settlements has explored how AI retrieval systems are reshaping risk analysis in financial infrastructure. At the applied layer, Ruh AI's work in financial services demonstrates how agentic AI powered by semantic retrieval is handling compliance verification and client intelligence in production environments.
Legal Technology Legal AI platforms use vector search to retrieve the most relevant case law, contract clauses, and regulatory text for a given legal question — enabling lawyers to research in minutes what previously took days. Contract review tools use vector similarity to flag unusual clauses by finding those that fall far from the cluster of standard language. Stanford's CodeX Center has documented how vector-based legal AI is transforming access to law.
E-Commerce and Retail Semantic product search, visual search (search by image), personalised recommendation engines, and inventory similarity analysis are all powered by vector databases. The customer experience delta between a keyword-search product catalogue and a vector-search one is measurable in conversion rates. McKinsey has estimated that personalisation engines — which rely heavily on vector similarity — drive 10–15% revenue uplifts for leading retailers.
Software Development and DevTools Code search tools like GitHub Copilot's context retrieval, documentation assistants, and debugging tools use vector databases to find semantically similar code snippets, relevant documentation sections, and analogous bug reports — based on the meaning of the code, not just syntax matching.
The Risks — What Nobody Tells You
The technology press covers the capabilities of vector databases extensively. The risks receive far less attention — which is a problem for any engineering team making production architectural decisions.
Risk 1: Garbage In, Garbage Out — Embedding Model Dependency
A vector database is only as good as the embeddings fed into it. If the embedding model is poorly matched to the domain (using a general-purpose text model for specialised medical literature, for example), the resulting vectors will not accurately capture the semantic relationships in your data. Searches will surface irrelevant results, RAG pipelines will retrieve wrong context, and no amount of database tuning will fix a fundamentally broken embedding layer. MTEB (Massive Text Embedding Benchmark) is the standard public leaderboard for evaluating embedding model quality across domains.
This risk is particularly acute for:
- Domain-specific vocabulary (legal, medical, financial) where general models may not capture specialist terminology relationships accurately
- Multilingual applications where embedding quality varies significantly across languages
- Code search where programming language semantics differ substantially from natural language
Risk 2: Chunking Strategy Failure in RAG Pipelines
In RAG applications, how you split documents into chunks before embedding is one of the most consequential and underappreciated architectural decisions. Get it wrong and retrieval quality collapses:
- Chunks too small (e.g., single sentences): Lose context. A sentence that says "This policy applies to all employees hired after the effective date" is meaningless without the surrounding paragraph.
- Chunks too large (e.g., full pages): The embedding averages over too many concepts, diluting the signal for any specific topic.
- Splitting mid-sentence or mid-table: Fragments semantically complete units, producing embeddings that represent partial ideas.
There is no universal correct chunk size. It is application-specific and requires systematic evaluation. LangChain's documentation on text splitters provides a practical reference for chunking strategies.
Risk 3: Approximate Search is Not Always Acceptable
HNSW's speed comes from approximation. For most applications — recommendation, semantic search, RAG — a 95–99% recall rate is entirely acceptable. Occasionally missing the single closest vector makes no practical difference.
But for compliance-critical applications — legal discovery, medical record search, regulatory audit — an approximate answer may be legally insufficient. "We found most of the relevant contracts" is not an acceptable answer in a litigation hold. Applications with hard recall requirements need to either use exact (brute-force) search on smaller datasets or implement recall verification mechanisms.
Risk 4: Memory and Cost at Scale
HNSW indexes are memory-resident for maximum performance. The memory requirement grows with both the number of vectors and their dimensionality. A dataset of 100 million 1,536-dimensional float32 vectors requires approximately 600 GB of raw storage — before indexing overhead, which can add another 50–100% depending on HNSW configuration parameters.
At this scale, self-hosted deployments on high-memory cloud instances become expensive. Managed services like Pinecone add a per-vector and per-query pricing model that can produce significant monthly bills for production workloads. Teams that prototype with free tiers and plan to scale without cost modelling often encounter unpleasant surprises. Pinecone's pricing page details current tier structures.
Risk 5: Data Staleness and Index Lag
Vector databases are not traditional OLTP systems. Adding or updating records is not simply an INSERT or UPDATE — it requires re-embedding the new content (an inference call to the embedding model), inserting the new vector, and potentially rebuilding or updating index structures. In high-throughput ingestion scenarios (real-time data pipelines), this can introduce meaningful lag between when data is added to the source system and when it becomes searchable.
For applications where data freshness is critical (financial news, live inventory, breaking news retrieval), this pipeline latency must be explicitly architected for.
Risk 6: Security, Compliance, and Access Control
Early vector database systems were built with a focus on performance and developer experience, not enterprise security. Some lacked role-based access control, encryption at rest, audit logging, and fine-grained permission management. The proprietary nature of embeddings also creates data governance questions: if a third-party embedding API generates vectors from your confidential documents, those documents are transmitted to an external service.
For regulated industries (healthcare HIPAA, financial services SOX, EU GDPR), due diligence on the security architecture of any vector database deployment is not optional.
Risk 7: Explainability and Debugging
When a SQL query returns the wrong row, you can trace exactly why. When a vector search returns an unexpected result, the reason lives inside hundreds or thousands of floating-point numbers interacting in ways that are not human-interpretable. Diagnosing relevance failures in vector search requires embedding visualisation tools, cosine similarity inspection, and often trial-and-error with chunking and indexing parameters. Tools like Arize AI and Weights & Biases provide observability tooling that can assist with embedding-space debugging in production.
Pros of Vector Databases
Semantic Understanding Searches by meaning, not keywords. "Car crash" and "automobile accident" are equivalent. "Cardiac arrest" surfaces "heart attack." A qualitative leap for any application handling natural language or complex content.
Millisecond Search at Billion Scale HNSW indexing enables similarity searches across hundreds of millions of vectors in under 10 milliseconds — a speed that brute-force approaches cannot come close to matching.
Reduces LLM Hallucinations RAG-powered applications that retrieve grounded, factual context from a vector database are measurably more accurate than base LLM responses on domain-specific questions.
Overcomes the LLM Knowledge Cutoff Update the vector database with new documents and the AI immediately has access — no fine-tuning, no retraining required.
Handles Unstructured Data Natively Documents, images, audio, emails, support tickets — 80%+ of enterprise data is unstructured. Vector databases are purpose-built for it, after embedding conversion.
Flexible Hybrid Search Semantic similarity combined with structured metadata filtering delivers results that are both conceptually relevant and precisely constrained — something neither SQL nor keyword search alone can achieve.
Language and Modality Agnostic A single vector database can serve multilingual text search, image similarity, code search, and cross-modal queries — with the right embedding models populating it.
Persistent, Updatable AI Memory Full CRUD support. Unlike temporary context windows, vector databases retain knowledge across sessions, with the ability to update, correct, or delete specific records.
Cons of Vector Databases
High Memory Requirements at Scale HNSW indexes are memory-resident. 100 million 1,536-dimensional vectors require hundreds of gigabytes of RAM before indexing overhead. Production-scale deployments are expensive to provision and operate.
Approximate Accuracy is a Real Limitation ANN algorithms trade perfect recall for speed. For compliance search, legal discovery, or medical record retrieval, "approximately complete results" may be legally or regulatorily unacceptable.
Entirely Dependent on Embedding Model Quality The database stores whatever it is given. A poorly matched embedding model — general-purpose models applied to specialised medical or legal vocabulary — produces vectors that do not accurately represent meaning. No database tuning fixes bad embeddings.
Chunking Configuration is Non-Trivial Chunks too small lose context; chunks too large dilute signal; splits mid-sentence corrupt semantics. Optimal chunking is application-specific and requires systematic evaluation — there are no universal defaults.
Cost Escalates Rapidly in Production Managed services price per vector and per query. At production scale, monthly bills grow quickly. Open-source self-hosted alternatives transfer the cost to engineering time and infrastructure management.
Ingestion Lag for Real-Time Data Every update requires re-embedding content, inserting vectors, and updating index structures — introducing pipeline latency between when data exists in the source system and when it becomes searchable.
Poor Explainability When vector search returns an unexpected result, the reason lives inside hundreds of floating-point numbers interacting in ways that are not human-interpretable. Debugging relevance issues requires specialised tooling and embedding-space intuition.
Not a Replacement for Traditional Databases Vector databases do not support ACID transactions, complex joins, or aggregate analytics. Production AI systems need both a vector database and a relational or document database — adding architectural and operational complexity.
Security Gaps in Some Solutions Some open-source solutions launched without enterprise-grade access control, audit logging, or encryption at rest. Regulated industries must audit the security posture of any solution before deploying sensitive data.
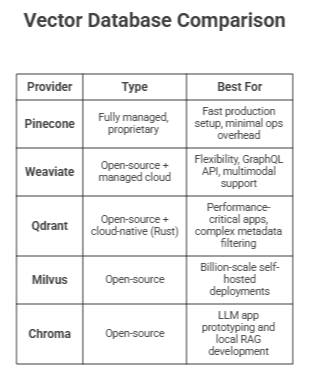
The Landscape
Dedicated Vector Databases
General-Purpose Databases With Vector Extensions

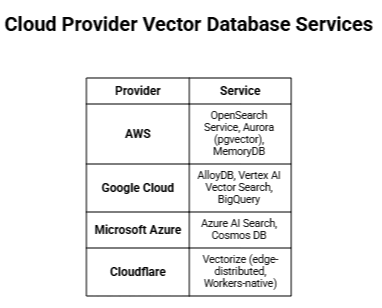
Cloud Provider Managed Services
What Comes Next
Five trends are reshaping the vector database landscape right now:
Multimodal Embeddings — Models like CLIP and ImageBind are converging text, images, audio, and video into unified embedding spaces. A single vector database will increasingly serve all modalities from one index.
Compression and Quantisation — Product quantisation is reducing memory requirements by 4–32x with minimal recall loss, making billion-scale deployments viable for a far wider range of organisations.
Hybrid Dense + Sparse Search as Default — Semantic dense vectors and keyword-precision sparse vectors are being combined in a single query path, delivering meaningfully better results than either approach alone.
Vector Databases as AI Memory Layers — The next wave of agentic AI treats vector databases as long-term episodic memory, not just document retrieval — storing past interactions and decisions that agents can reason over across sessions.
Convergence With Traditional Databases — Every major relational and document database (PostgreSQL, MongoDB, Cosmos DB) is adding native vector search. Whether standalone vector databases remain a distinct category or get absorbed into general-purpose platforms is the defining infrastructure question of the next few years.
How Ruh AI Is Putting Vector Databases to Work in Agentic and Generative AI
Most organisations understand that vector databases matter. Far fewer know how to deploy them inside production AI systems that actually act rather than just retrieve. That is the gap Ruh AI is built to close — building autonomous AI employees that run complex, multi-step workflows across financial services, healthcare, sales, and marketing, with vector databases as the cognitive backbone.
AI Employees That Remember Standard LLM chatbots start every conversation from zero. Ruh AI's agents do not. Past interactions, prospect history, policy documents, and domain knowledge are all stored as embeddings — retrieved semantically on every touchpoint. Ruh AI's AI SDR platform and its autonomous agent Sarah use this architecture to personalise outreach at a depth no human team can match at scale. As Ruh AI's analysis of cold email in 2026 makes clear, contextual retrieval is precisely what separates AI outreach that converts from AI outreach that gets ignored.
When Retrieval Becomes Decision-Making RAG was the first wave. Agentic AI is the next — systems that retrieve context, evaluate options, call external tools, and update their own memory in a continuous loop. Ruh AI's complete AI implementation guide explains why this shift demands a fundamentally different retrieval architecture. Their analysis of AI agents that refuse commands pinpoints exactly what breaks when agentic systems lack proper vector memory — agents acting on incomplete context, failing silently, or rejecting instructions they should be able to resolve.
Sector Applications In financial services, Ruh AI's agents handle regulatory lookup, compliance verification, and fraud-pattern recognition — workflows where retrieval accuracy is tied directly to legal risk. In healthcare, the same agents surface clinically relevant context to support human decision-making without replacing it. Both sectors represent the high-stakes end of what vector-backed agentic AI can do in production.
Self-Improving Systems and Prompt Architecture Vector databases are not static. Ruh AI's work on AI in MLOps and self-improving agents via RLHF shows how retrieval quality improves over time as embedding stores are updated from real-world feedback. And their prompt engineering guide for autonomous agents makes the case that how you instruct an agent to query its memory is as consequential as the retrieval infrastructure itself.
Customer Intelligence Vector databases also drive Ruh AI's customer-facing capabilities. Customer journey mapping with AI uses evolving customer embeddings to surface the right next action at every stage. Their work on eliminating marketing operations bottlenecks applies semantic campaign analysis — measuring embedding similarity across audiences rather than keyword frequency — to unlock optimisation that rules-based systems cannot reach.
Vector databases are not just infrastructure for Ruh AI — they are the cognitive substrate that determines whether an AI agent performs or merely responds. Explore their blog for deeper implementation guidance, or get in touch if your organisation is ready to move from pilot to production.
Final Word
Vector databases are not a trend. They are not a hype cycle. They are infrastructure — the kind of infrastructure that quietly becomes foundational and invisible, like TCP/IP or the relational model, because the applications built on top of them could not exist without them.
Every time you get a recommendation that feels uncannily right. Every time an AI assistant answers a question about your specific company's data accurately. Every time a fraud alert fires before a criminal transaction completes. Every time a search engine understands what you meant rather than just what you typed — there is a vector database involved somewhere in that stack.
The organisations that understand this infrastructure deeply, build on it deliberately, and architect their AI systems with an honest understanding of both its extraordinary capabilities and its genuine limitations will be the ones that build AI applications that actually work in production.
The ones that treat it as magic will ship demos that impress and products that disappoint.
Understanding vector databases is no longer optional for anyone building seriously in AI. It is table stakes.
FAQ
1. What is a vector database in simple terms?
Ans: A vector database is a system that stores data as numerical representations (embeddings) and retrieves information based on meaning rather than exact matches. It helps AI systems find the most relevant results even when the wording is different.
2. How are vector databases different from traditional databases?
Ans: Traditional databases (like SQL) search for exact matches using structured queries, while vector databases perform similarity searches using mathematical distance between embeddings—allowing them to understand context, semantics, and relationships.
3. Why are vector databases important for AI applications?
Ans: They act as the memory layer for AI systems, enabling:
- Retrieval-Augmented Generation (RAG)
- Semantic search
- Personalized recommendations
Without vector databases, modern AI systems would lack real-time and domain-specific knowledge.
4. What is an embedding in a vector database?
Ans: An embedding is a list of numbers that represents the meaning of data (text, image, audio). Similar data points have embeddings that are mathematically close to each other in vector space.
5. What is similarity search?
Ans: Similarity search finds data points that are closest in meaning to a query by comparing embeddings using metrics like cosine similarity or Euclidean distance.
6. What is HNSW indexing and why is it used?
Ans: HNSW (Hierarchical Navigable Small World) is an advanced indexing algorithm that enables ultra-fast approximate nearest neighbor search. It drastically reduces computation time from millions of comparisons to just hundreds.
7. What is Retrieval-Augmented Generation (RAG)?
Ans: RAG is an AI architecture where:
Data is stored in a vector database
Relevant information is retrieved at query time
That context is fed into a language model
This makes AI responses more accurate and grounded in real data.
8. What are the main use cases of vector databases?
Ans: Common applications include:
- Semantic search engines
- AI chatbots and assistants
- Recommendation systems (Netflix, Amazon)
- Fraud detection
- Image and voice recognition
- Legal and healthcare research tools
9. What are the biggest challenges of using vector databases?
Ans: Key challenges include:
- Dependence on embedding quality
- Complex chunking strategies
- High memory and infrastructure costs
- Approximate search limitations
- Difficulty in debugging and explainability
10. Are vector databases always accurate?
Ans: Not always. Most use approximate search algorithms, which trade perfect accuracy for speed. For critical use cases (legal, medical), additional validation mechanisms may be required.
11. What are some popular vector database tools?
Ans: Popular options include:
- Pinecone
- Weaviate
- Qdrant
- Milvus
- Chroma
Additionally, tools like PostgreSQL (pgvector) and MongoDB Atlas now support vector search.