





TL; DR / Summary
AI agents are transforming how businesses operate from customer service bots to autonomous research assistants. But here's the critical question: how do you know if your AI agent actually works?
Traditional software testing isn't enough because AI agents are probabilistic and adaptive, so their behavior can vary significantly with context. Unlike regular programs that give the same output for the same input, AI agents make autonomous decisions, use external tools, and adapt based on memory and context.
In this guide, we'll break down exactly how to evaluate AI agents through three fundamental capabilities: perception (understanding), planning (reasoning), and action (execution). Whether you're building your first agent with Ruh.AI or scaling enterprise systems, this framework will help you ship reliable, trustworthy AI.
Ready to see how it all works? Here’s a breakdown of the key elements:
- What is AI Agent Evaluation?
- The Critical Challenge: Multi-Dimensional Assessment
- The Three Pillars of Agent Evaluation
- Building Your Evaluation Framework: A Practical Approach
- Essential Metrics to Track
- Implementation Roadmap: Your 4-Week Plan
- Choosing the Right Evaluation Tools
- Best Practices from Leading AI Teams
- Common Pitfalls to Avoid
- Real-World Success Story
- The Future of Agent Evaluation
- Getting Started Today
- Frequently Asked Questions
What is AI Agent Evaluation?
Think of AI agent evaluation as quality control for intelligent systems. But instead of testing if code runs correctly, you're assessing whether an agent:
- Understands its environment accurately (perception)
- Makes smart decisions (planning)
- Takes the right actions (execution)
AI agent evaluation is about ensuring an agent is doing the right things (effectiveness) in the right way (efficiency, safety). This includes measuring technical performance, validating human oversight levels, and confirming business impact.
Why Traditional Testing Fails
Regular software testing uses simple rules: give it input X, expect output Y. AI agents break these rules because they:
- Produce different outputs for the same input due to randomness in language models
- Use multiple tools in varying sequences (APIs, databases, web searches)
- Remember context from previous interactions that affects decisions
- Adapt dynamically based on environment changes
A customer service agent might handle the same complaint differently based on conversation history, time of day, or available resources. This complexity demands new evaluation approaches.
The Critical Challenge: Multi-Dimensional Assessment
AI agent evaluation encompasses multiple dimensions of assessment—from the agent's raw technical capabilities to its degree of autonomy and its alignment with human expectations.
Consider an AI sales assistant like Ruh.AI's SDR Sarah. You need to evaluate:
Technical Level:
- Does it accurately extract lead information? (Perception)
- Can it create effective email sequences? (Planning)
- Does it send messages without errors? (Action)
Autonomy Level:
- Should it require approval before sending emails?
- Can it make pricing decisions independently?
- When should it escalate to humans?
This dual framework—capability assessment plus autonomy evaluation—forms the foundation of modern agent testing.
The Three Pillars of Agent Evaluation
Every AI agent operates through three core capabilities. Here's how to test each one:
Pillar 1: Evaluating Perception
What is perception? How your agent senses and interprets its environment reading messages, analyzing data, understanding context.
Why it matters: If perception fails, everything downstream breaks. An agent that misunderstands "cancel my order" as "can you sell my order" will cause serious problems.
Key Perception Tests:
Input Understanding:
- Handles different formats (text, voice, structured data)
- Interprets ambiguous requests correctly
- Identifies true user intent behind queries
Context Awareness:
- Maintains conversation history accurately
- Retrieves relevant past information
- Recognizes when context has shifted
Example Evaluation:
User Query: "It's not working" Good Perception: Identifies ambiguity, asks clarifying questions, checks recent activity Poor Perception: Assumes what "it" refers to, provides generic troubleshooting
Platforms like Ruh.AI's Work Lab help teams test perception accuracy across diverse scenarios before production deployment.
Pillar 2: Evaluating Planning
What is planning? Your agent's ability to reason through problems, break down complex tasks, and choose optimal strategies.
Planning involves evaluating the technical performance of the agent's components and overall task success rates, ensuring the agent takes efficient paths to goals.
Key Planning Tests:
Reasoning Quality:
- Breaks complex tasks into logical steps
- Considers multiple solution approaches
- Explains decision-making process clearly
Tool Selection:
- Chooses appropriate tools for each sub-task
- Chains tools together effectively
- Avoids unnecessary or redundant steps
Adaptability:
- Revises plans when conditions change
- Recovers gracefully from errors
- Optimizes approach based on feedback
Real-World Example:
Task: "Research competitor pricing and create a report"
Well-Planned Agent:
- Identifies key competitors
- Searches reliable pricing sources
- Cross-references data
- Structures findings logically
- Generates formatted report
Poorly-Planned Agent:
- Uses single outdated source
- Includes irrelevant competitors
- Presents unstructured data dump
- Gets stuck in information loops
For marketing teams, Ruh.AI's Marketing solutions demonstrate how proper planning enables agents to execute complex campaigns autonomously.
Pillar 3: Evaluating Action
What is action? The specific executions your agent performs—API calls, database updates, message sending, file creation.
Actions are where theoretical planning meets real-world impact. A single wrong function call can expose sensitive data or trigger costly mistakes.
Key Action Tests:
Execution Accuracy:
- Calls correct functions with valid parameters
- Handles API responses appropriately
- Manages errors without cascading failures
Safety and Constraints:
- Respects user permissions and access controls
- Identifies risky actions before executing
- Follows organizational policies strictly
Function Calling Metrics
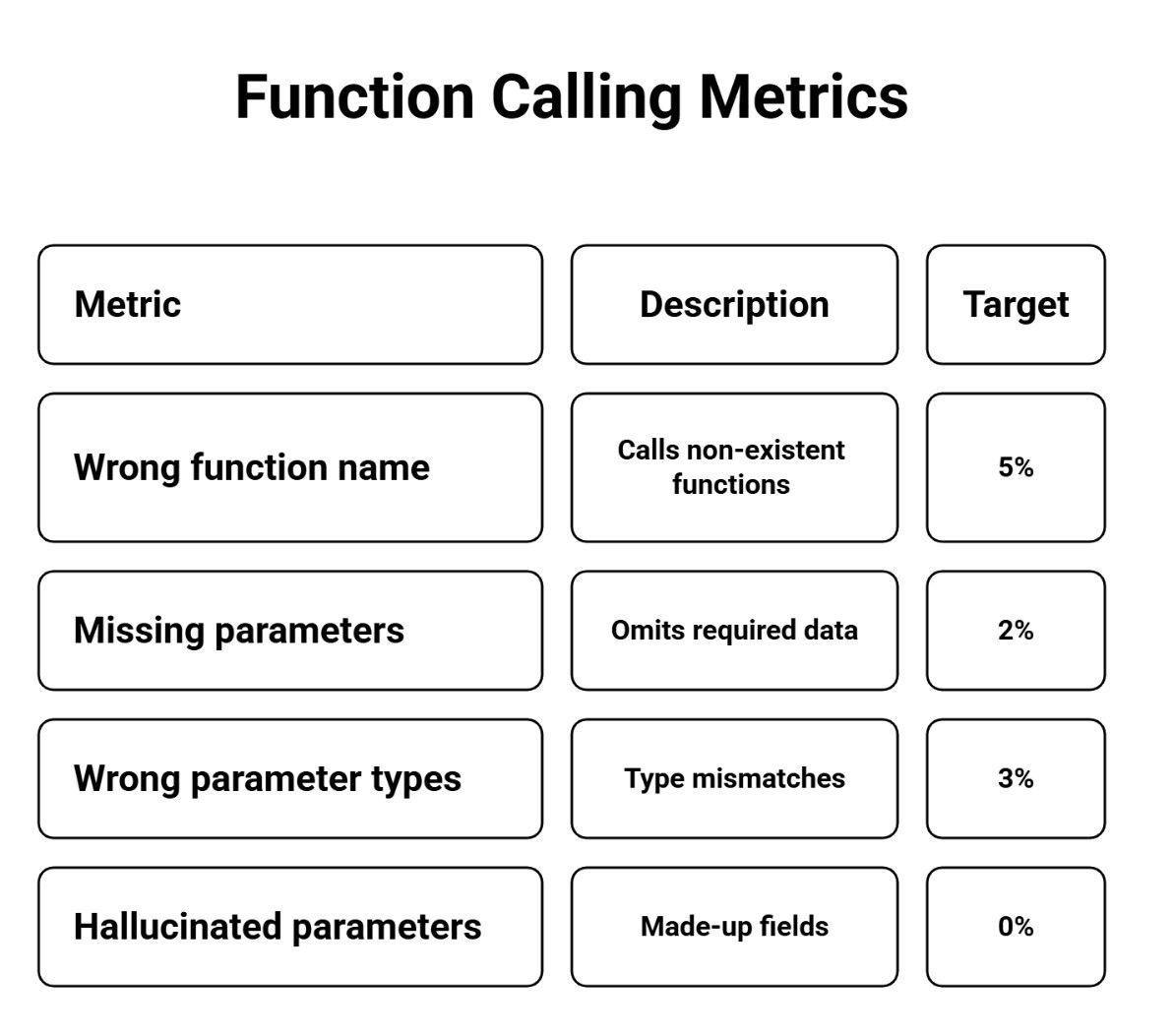
Example Test Case:
Task: Book meeting with client Correct: create_event(title="Client Meeting", date="2024-12-20", duration=60) Wrong: schedule_meeting(name="meeting", when="next week", length="1 hour")
For development teams, Ruh.AI's Developer tools provide structured APIs that enforce parameter validation automatically.
Building Your Evaluation Framework: A Practical Approach
Now let's build a complete testing strategy using the three-level approach recommended by leading AI teams:
Level 1: Component Testing
Test individual capabilities in isolation.
- Perception modules with diverse inputs
- Planning logic with hypothetical scenarios
- Action modules with mock APIs
Benefit: Catches issues early when they're cheap to fix.
Level 2: Integration Testing
Verify components work together correctly.
- Data flows between perception → planning → action
- State management across conversation turns
- Format compatibility between modules
Benefit: Identifies handoff failures before production.
Level 3: End-to-End Testing
Simulate complete user workflows.
- Multi-turn conversations with real scenarios
- Edge cases and error conditions
- Performance under production-like loads
Benefit: Validates actual user experience.
By following best practices such as tracking multiple metrics, using baselines, automating evaluations, and logging detailed traces, developers can systematically improve their agents.
Essential Metrics to Track
Combining various metrics from latency and cost to accuracy and robustness—offers a well-rounded view of an agent's performance.
Core Performance Metrics
Task Success Rate
- Percentage of completed tasks
- Target: 85-95% for production
- Measured against expected outcomes
Accuracy & Relevance
- Factual correctness of responses
- Target: >95% for factual queries
- Evaluated via LLM-as-judge or human review
Efficiency Metrics
- Steps to completion (fewer is better)
- Response latency (target: <2 seconds)
- Cost per task (tokens, API calls)
Safety & Reliability Metrics
Hallucination Rate
- Frequency of fabricated information
- Target: <1% for production
- Critical for high-stakes applications
Policy Compliance
- Adherence to organizational rules
- Regulatory compliance (GDPR, HIPAA)
- Ethical AI guidelines
Robustness Score
- Performance consistency across scenarios
- Error recovery success rate
- Graceful degradation under load
For AI SDR applications like Ruh.AI's AI-SDR, these metrics ensure reliable, compliant outreach at scale.
Implementation Roadmap: Your 4-Week Plan
Week 1: Foundation
- Set up logging and observability
- Define success criteria for your use case
- Establish baseline performance metrics
Week 2: Component Testing
- Create test cases for perception, planning, action
- Implement automated test suites
- Run initial evaluations and document results
Week 3: Integration & End-to-End
- Test component interactions
- Simulate real user workflows
- Add adversarial and edge case testing
Week 4: Production Readiness
- Set up monitoring dashboards
- Configure alerts for critical metrics
- Deploy with gradual rollout strategy
Pro Tip: Platforms like Ruh.AI provide integrated evaluation environments that compress this timeline by offering pre-built testing frameworks and monitoring tools.
Choosing the Right Evaluation Tools
The evaluation tool landscape includes both open-source frameworks and commercial platforms:
Open-Source Options:
- LangChain/LangGraph: Flexible for custom workflows
- Promptfoo: Fast prompt-level testing
- DeepEval: Comprehensive agent evaluation
Commercial Platforms:
- Weights & Biases (W&B Weave): Experiment tracking and metrics visualization
- Arize AI: Strong observability and drift detection
- Ruh.AI: Unified evaluation, deployment, and monitoring
Selection Criteria:
- Team technical expertise
- Budget and pricing model
- Integration with existing stack
- Support for your agent architecture
For technology teams exploring comprehensive solutions, Ruh.AI's Technology platform offers end-to-end evaluation and deployment capabilities.
Best Practices from Leading AI Teams
Consistent evaluation lets us compare different agents or techniques fairly. Here's what works:
1. Automate Continuously
Run evaluations on every code change, not just before major releases. Catch regressions early.
2. Use Baselines
Compare new versions against established benchmarks. Track improvements over time.
3. Log Everything
Capture detailed traces including inputs, reasoning steps, tool calls, and outputs. Essential for debugging.
4. Combine Automated + Human Review
Automation scales testing; humans catch nuanced issues like tone, bias, and edge cases.
5. Test in Production
Monitor real user interactions. Production data reveals issues testing environments miss.
6. Iterate Based on Data
Reliable metrics allow developers to iterate and improve the agent. Use evaluation results to guide development priorities.
Common Pitfalls to Avoid
1. Testing Only Final Outputs
Problem: Ignores how agents reached conclusions Solution: Evaluate reasoning paths, tool selection, and intermediate steps
2. Insufficient Coverage
Problem: Only testing happy paths Solution: Dedicate 40% of tests to edge cases and adversarial inputs
3. Ignoring Resource Costs
Problem: Technically correct but expensive agents fail at scale Solution: Track token usage, API calls, and latency from day one
4. No Production Monitoring
Problem: Assuming testing ends at deployment Solution: Implement continuous monitoring with real-time alerts
Real-World Success Story
Challenge: A B2B company built an AI sales agent that achieved only 62% task completion in testing—insufficient for production.
Evaluation Overhaul:
Phase 1: Perception Improvements
- Added multi-format input handling
- Improved context retrieval accuracy
- Result: Understanding increased from 67% to 91%
Phase 2: Planning Optimization
- Implemented step-by-step reasoning validation
- Added tool selection benchmarks
- Result: Reduced unnecessary actions by 38%
Phase 3: Action Validation
- Created comprehensive function testing
- Added safety guardrails
- Result: Eliminated parameter errors
Final Results:
- Task completion: 91%
- User satisfaction: 4.4/5
- 52% faster than human baseline
- $0.09 cost per interaction
Key Takeaway: Systematic evaluation across perception, planning, and action transformed an unreliable prototype into a production-ready system.
The Future of Agent Evaluation
As AI agents become more sophisticated, evaluation frameworks are evolving:
Emerging Trends:
- Self-evaluation agents that assess their own performance
- Multi-agent evaluation for collaborative systems
- Regulatory compliance testing for EU AI Act and similar laws
- Real-time adaptation with human oversight for critical decisions
Organizations that invest in robust evaluation frameworks today will lead tomorrow's AI landscape.
Getting Started Today
Evaluating AI agents doesn't have to be overwhelming. Start with these three actions:
- Set up basic observability - Log agent decisions and actions
- Define 3-5 critical metrics - Focus on what matters most for your use case
- Create 10-20 test scenarios - Cover standard cases and edge conditions
Remember: every production-ready agent started with basic testing. The key is consistent, iterative improvement.
Need help implementing agent evaluation? Contact Ruh.AI to learn how our platform simplifies testing, deployment, and monitoring for AI agents.
For more insights on building reliable AI systems, explore our blog or learn about our comprehensive approach to AI agent development.
Frequently Asked Questions
How is agent evaluation different from LLM evaluation?
Ans: LLM evaluation focuses on text quality. Agent evaluation assesses complete workflows including reasoning, tool usage, and multi-step task completion.
What's the minimum success rate for production?
Ans: Aim for 85-90% on standard tasks. For critical applications (healthcare, finance), require 95%+ accuracy.
How often should I run evaluations?
Ans: Automated tests on every code change, comprehensive evaluations nightly, and human reviews weekly.
Can non-technical teams evaluate agents
Ans: Yes! Platforms like Ruh.AI offer user-friendly interfaces for evaluation without requiring coding expertis